 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery of Important Subsequences in Electrocardiogram Beats Using the Nearest Neighbour Algorithm
Jan 26, 2019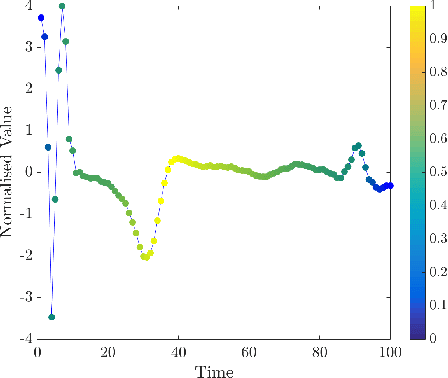


The classification of time series data is a well-studied problem with numerous practical applications, such as medical diagnosis and speech recognition. A popular and effective approach is to classify new time series in the same way as their nearest neighbours, whereby proximity is defined using Dynamic Time Warping (DTW) distance, a measure analogous to sequence alignment in bioinformatics. However, practitioners are not only interested in accurate classification, they are also interested in why a time series is classified a certain way. To this end, we introduce here the problem of finding a minimum length subsequence of a time series, the removal of which changes the outcome of the classification under the nearest neighbour algorithm with DTW distance. Informally, such a subsequence is expected to be relevant for the classification and can be helpful for practitioners in interpreting the outcome. We describe a simple but optimized implementation for detecting these subsequences and define an accompanying measure to quantify the relevance of every time point in the time series for the classification. In tests on electrocardiogram data we show that the algorithm allows discovery of important subsequences and can be helpful in detecting abnormalities in cardiac rhythms distinguishing sick from healthy patients.