 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Property Valuation Models via Graph-based Deep Learning
May 10, 2024



This paper aims to enrich the capabilities of existing deep learning-based automated valuation models through an efficient graph representation of peer dependencies, thus capturing intricate spatial relationships. In particular, we develop two novel graph neural network models that effectively identify sequences of neighboring houses with similar features, employing different message passing algorithms. The first strategy consider standard spatial graph convolutions, while the second one utilizes transformer graph convolutions. This approach confers scalability to the modeling process. The experimental evaluation is conducted using a proprietary dataset comprising approximately 200,000 houses located in Santiago, Chile. We show that employing tailored graph neural networks significantly improves the accuracy of house price prediction, especially when utilizing transformer convolutional message passing layers.
A predict-and-optimize approach to profit-driven churn prevention
Oct 10, 2023In this paper, we introduce a novel predict-and-optimize method for profit-driven churn prevention. We frame the task of targeting customers for a retention campaign as a regret minimization problem. The main objective is to leverage individual customer lifetime values (CLVs) to ensure that only the most valuable customers are targeted. In contrast, many profit-driven strategies focus on churn probabilities while considering average CLVs. This often results in significant information loss due to data aggregation. Our proposed model aligns with the guidelines of Predict-and-Optimize (PnO) frameworks and can be efficiently solved using stochastic gradient descent methods. Results from 12 churn prediction datasets underscore the effectiveness of our approach, which achieves the best average performance compared to other well-established strategies in terms of average profit.
Efficient Hybrid Oversampling and Intelligent Undersampling for Imbalanced Big Data Classification
Oct 09, 2023Imbalanced classification is a well-known challenge faced by many real-world applications. This issue occurs when the distribution of the target variable is skewed, leading to a prediction bias toward the majority class. With the arrival of the Big Data era, there is a pressing need for efficient solutions to solve this problem. In this work, we present a novel resampling method called SMOTENN that combines intelligent undersampling and oversampling using a MapReduce framework. Both procedures are performed on the same pass over the data, conferring efficiency to the technique. The SMOTENN method is complemented with an efficient implementation of the neighborhoods related to the minority samples. Our experimental results show the virtues of this approach, outperforming alternative resampling techniques for small- and medium-sized datasets while achieving positive results on large datasets with reduced running times.
OWAdapt: An adaptive loss function for deep learning using OWA operators
May 30, 2023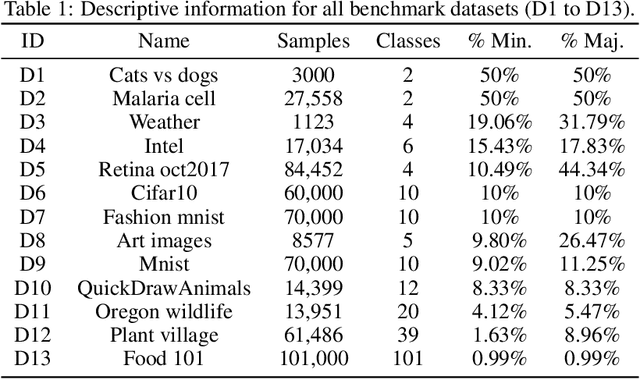
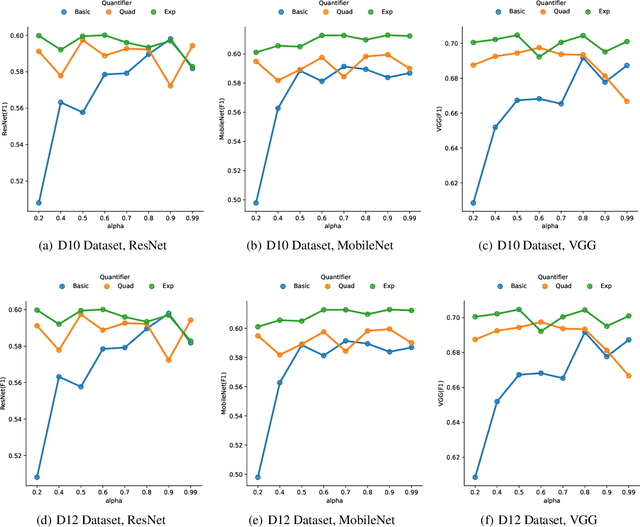
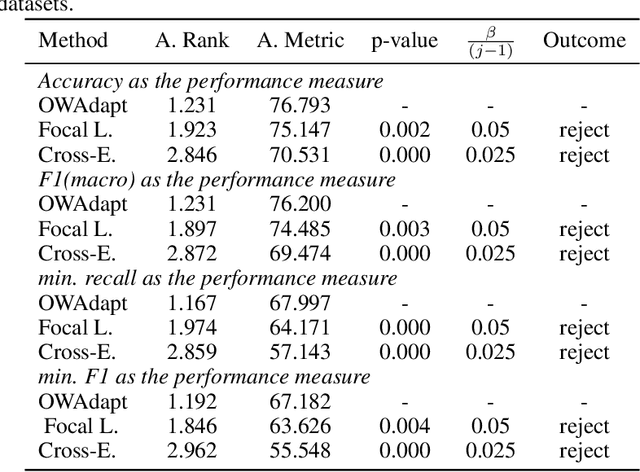

In this paper, we propose a fuzzy adaptive loss function for enhancing deep learning performance in classification tasks. Specifically, we redefine the cross-entropy loss to effectively address class-level noise conditions, including the challenging problem of class imbalance. Our approach introduces aggregation operators, leveraging the power of fuzzy logic to improve classification accuracy. The rationale behind our proposed method lies in the iterative up-weighting of class-level components within the loss function, focusing on those with larger errors. To achieve this, we employ the ordered weighted average (OWA) operator and combine it with an adaptive scheme for gradient-based learning. Through extensive experimentation, our method outperforms other commonly used loss functions, such as the standard cross-entropy or focal loss, across various binary and multiclass classification tasks. Furthermore, we explore the influence of hyperparameters associated with the OWA operators and present a default configuration that performs well across different experimental settings.
Automatic learning algorithm selection for classification via convolutional neural networks
May 16, 2023As in any other task, the process of building machine learning models can benefit from prior experience. Meta-learning for classifier selection gains knowledge from characteristics of different datasets and/or previous performance of machine learning techniques to make better decisions for the current modeling process. Meta-learning approaches first collect meta-data that describe this prior experience and then use it as input for an algorithm selection model. In this paper, however, we propose an automatic learning scheme in which we train convolutional networks directly with the information of tabular datasets for binary classification. The goal of this study is to learn the inherent structure of the data without identifying meta-features. Experiments with simulated datasets show that the proposed approach achieves nearly perfect performance in identifying linear and nonlinear patterns, outperforming the traditional two-step method based on meta-features. The proposed method is then applied to real-world datasets, making suggestions about the best classifiers that can be considered based on the structure of the data.