 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Philosophical Introduction to Language Models -- Part I: Continuity With Classic Debates
Jan 08, 2024Large language models like GPT-4 have achieved remarkable proficiency in a broad spectrum of language-based tasks, some of which are traditionally associated with hallmarks of human intelligence. This has prompted ongoing disagreements about the extent to which we can meaningfully ascribe any kind of linguistic or cognitive competence to language models. Such questions have deep philosophical roots, echoing longstanding debates about the status of artificial neural networks as cognitive models. This article -- the first part of two companion papers -- serves both as a primer on language models for philosophers, and as an opinionated survey of their significance in relation to classic debates in the philosophy cognitive science, artificial intelligence, and linguistics. We cover topics such as compositionality, language acquisition, semantic competence, grounding, world models, and the transmission of cultural knowledge. We argue that the success of language models challenges several long-held assumptions about artificial neural networks. However, we also highlight the need for further empirical investigation to better understand their internal mechanisms. This sets the stage for the companion paper (Part II), which turns to novel empirical methods for probing the inner workings of language models, and new philosophical questions prompted by their latest developments.
Adversarial Examples and the Deeper Riddle of Induction: The Need for a Theory of Artifacts in Deep Learning
Mar 20, 2020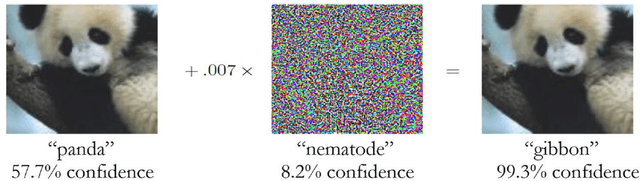


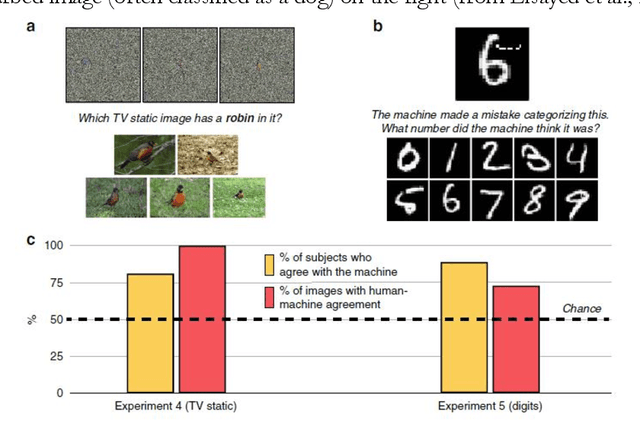
Deep learning is currently the most widespread and successful technology in artificial intelligence. It promises to push the frontier of scientific discovery beyond current limits. However, skeptics have worried that deep neural networks are black boxes, and have called into question whether these advances can really be deemed scientific progress if humans cannot understand them. Relatedly, these systems also possess bewildering new vulnerabilities: most notably a susceptibility to "adversarial examples". In this paper, I argue that adversarial examples will become a flashpoint of debate in philosophy and diverse sciences. Specifically, new findings concerning adversarial examples have challenged the consensus view that the networks' verdicts on these cases are caused by overfitting idiosyncratic noise in the training set, and may instead be the result of detecting predictively useful "intrinsic features of the data geometry" that humans cannot perceive (Ilyas et al., 2019). These results should cause us to re-examine responses to one of the deepest puzzles at the intersection of philosophy and science: Nelson Goodman's "new riddle" of induction. Specifically, they raise the possibility that progress in a number of sciences will depend upon the detection and manipulation of useful features that humans find inscrutable. Before we can evaluate this possibility, however, we must decide which (if any) of these inscrutable features are real but available only to "alien" perception and cognition, and which are distinctive artifacts of deep learning-for artifacts like lens flares or Gibbs phenomena can be similarly useful for prediction, but are usually seen as obstacles to scientific theorizing. Thus, machine learning researchers urgently need to develop a theory of artifacts for deep neural networks, and I conclude by sketching some initial directions for this area of research.