 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Agents, Language, Deep Learning and the Next Revolution in Science
Mar 09, 2026Modern science is reaching a critical inflection point. Instruments across disciplines, from particle physics and astronomy to genomics and climate modeling, now produce data of such scale, diversity, and interdependence that traditional analytical methods can no longer keep pace. This growing imbalance between data generation and data understanding signals the need for a new scientific paradigm. We propose that intelligent, human-supervised AI agents operating over deep-learning algorithms, represent the next evolution of the scientific method. Built upon large language models and multimodal learning, these agents can interpret scientific intent, design and execute analytical workflows, and ensure traceability through domain-specific languages that preserve human oversight and accountability. Particle physics, a historic incubator of computational innovation, offers the ideal testbed for this transition. At the Institute of High Energy Physics of the Chinese Academy of Sciences, the Dr. Sai system embodies this vision, a multi-agent reasoning framework deployed within collider research at the CEPC. This emerging approach does not replace human scientists but extends their cognitive reach, enabling discovery to scale with complexity and redefining how knowledge itself is produced in the age of intelligent machines. The significance of this paradigm transcends particle physics, offering a blueprint for all data-driven sciences facing the same complexity ceiling.
* This perspective paper is accepted by Frontier of Physics
COVID-19 South African Vaccine Hesitancy Models Show Boost in Performance Upon Fine-Tuning on M-pox Tweets
Oct 04, 2023Very large numbers of M-pox cases have, since the start of May 2022, been reported in non-endemic countries leading many to fear that the M-pox Outbreak would rapidly transition into another pandemic, while the COVID-19 pandemic ravages on. Given the similarities of M-pox with COVID-19, we chose to test the performance of COVID-19 models trained on South African twitter data on a hand-labelled M-pox dataset before and after fine-tuning. More than 20k M-pox-related tweets from South Africa were hand-labelled as being either positive, negative or neutral. After fine-tuning these COVID-19 models on the M-pox dataset, the F1-scores increased by more than 8% falling just short of 70%, but still outperforming state-of-the-art models and well-known classification algorithms. An LDA-based topic modelling procedure was used to compare the miss-classified M-pox tweets of the original COVID-19 RoBERTa model with its fine-tuned version, and from this analysis, we were able to draw conclusions on how to build more sophisticated models.
Detecting the Presence of COVID-19 Vaccination Hesitancy from South African Twitter Data Using Machine Learning
Jul 12, 2023

Very few social media studies have been done on South African user-generated content during the COVID-19 pandemic and even fewer using hand-labelling over automated methods. Vaccination is a major tool in the fight against the pandemic, but vaccine hesitancy jeopardizes any public health effort. In this study, sentiment analysis on South African tweets related to vaccine hesitancy was performed, with the aim of training AI-mediated classification models and assessing their reliability in categorizing UGC. A dataset of 30000 tweets from South Africa were extracted and hand-labelled into one of three sentiment classes: positive, negative, neutral. The machine learning models used were LSTM, bi-LSTM, SVM, BERT-base-cased and the RoBERTa-base models, whereby their hyperparameters were carefully chosen and tuned using the WandB platform. We used two different approaches when we pre-processed our data for comparison: one was semantics-based, while the other was corpus-based. The pre-processing of the tweets in our dataset was performed using both methods, respectively. All models were found to have low F1-scores within a range of 45$\%$-55$\%$, except for BERT and RoBERTa which both achieved significantly better measures with overall F1-scores of 60$\%$ and 61$\%$, respectively. Topic modelling using an LDA was performed on the miss-classified tweets of the RoBERTa model to gain insight on how to further improve model accuracy.
The use of Generative Adversarial Networks to characterise new physics in multi-lepton final states at the LHC
May 31, 2021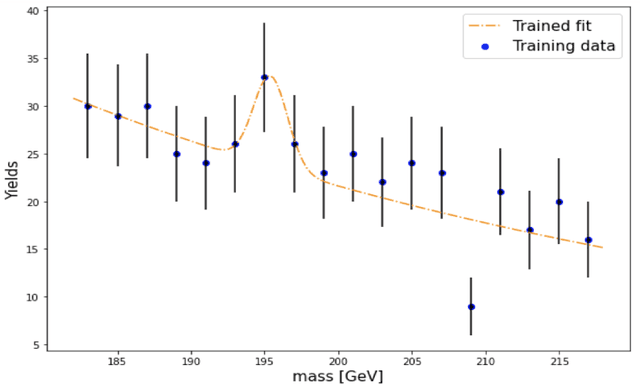
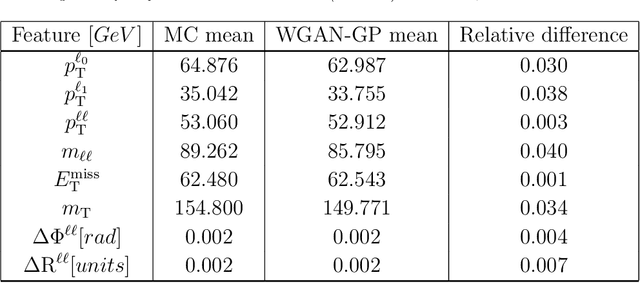
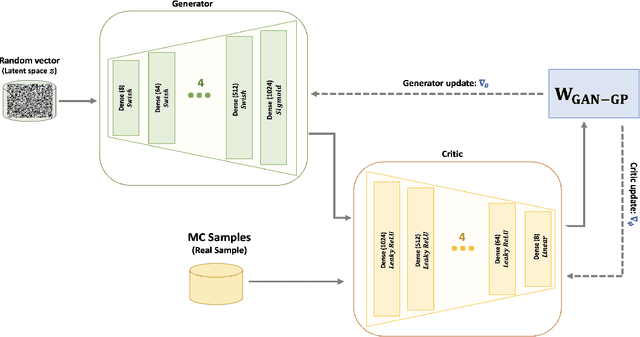
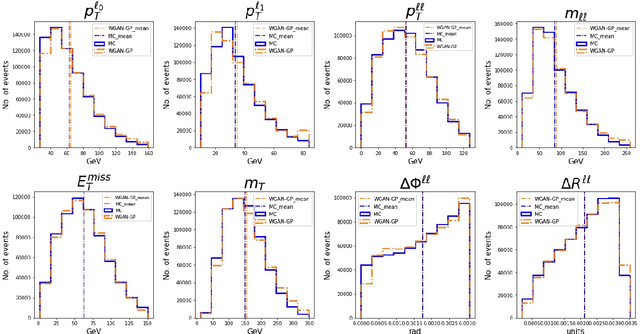
Semi-supervision in Machine Learning can be used in searches for new physics where the signal plus background regions are not labelled. This strongly reduces model dependency in the search for signals Beyond the Standard Model. This approach displays the drawback in that over-fitting can give rise to fake signals. Tossing toy Monte Carlo (MC) events can be used to estimate the corresponding trials factor through a frequentist inference. However, MC events that are based on full detector simulations are resource intensive. Generative Adversarial Networks (GANs) can be used to mimic MC generators. GANs are powerful generative models, but often suffer from training instability. We henceforth show a review of GANs. We advocate the use of Wasserstein GAN (WGAN) with weight clipping and WGAN with gradient penalty (WGAN-GP) where the norm of gradient of the critic is penalized with respect to its input. Following the emergence of multi-lepton anomalies at the LHC, we apply GANs for the generation of di-leptons final states in association with b-quarks at the LHC. A good agreement between the MC events and the WGAN-GP events is found for the observables selected in the study.