 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Unwanted Biases with Adversarial Learning
Jan 22, 2018
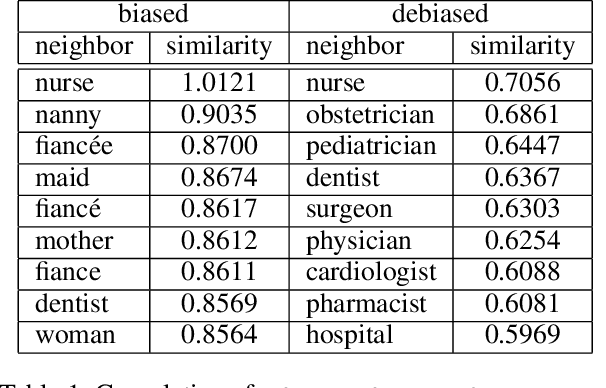
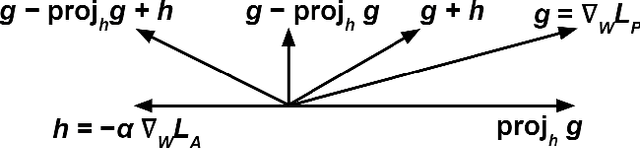
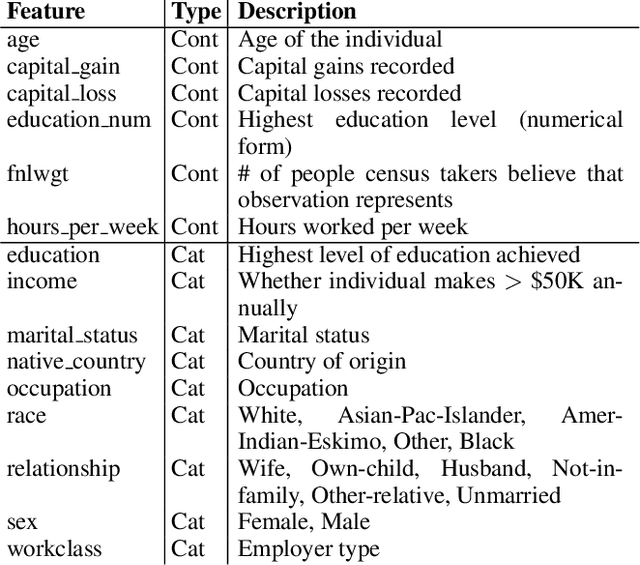
Machine learning is a tool for building models that accurately represent input training data. When undesired biases concerning demographic groups are in the training data, well-trained models will reflect those biases. We present a framework for mitigating such biases by including a variable for the group of interest and simultaneously learning a predictor and an adversary. The input to the network X, here text or census data, produces a prediction Y, such as an analogy completion or income bracket, while the adversary tries to model a protected variable Z, here gender or zip code. The objective is to maximize the predictor's ability to predict Y while minimizing the adversary's ability to predict Z. Applied to analogy completion, this method results in accurate predictions that exhibit less evidence of stereotyping Z. When applied to a classification task using the UCI Adult (Census) Dataset, it results in a predictive model that does not lose much accuracy while achieving very close to equality of odds (Hardt, et al., 2016). The method is flexible and applicable to multiple definitions of fairness as well as a wide range of gradient-based learning models, including both regression and classification tasks.