 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORCHARD: A Benchmark For Measuring Systematic Generalization of Multi-Hierarchical Reasoning
Nov 28, 2021
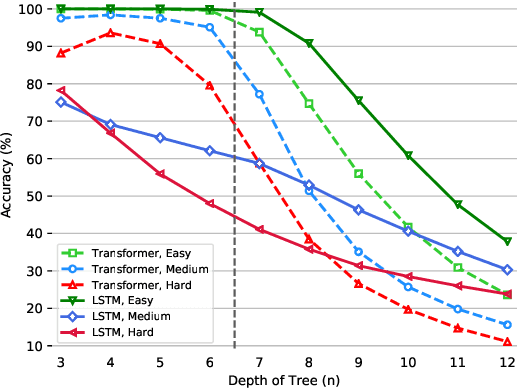
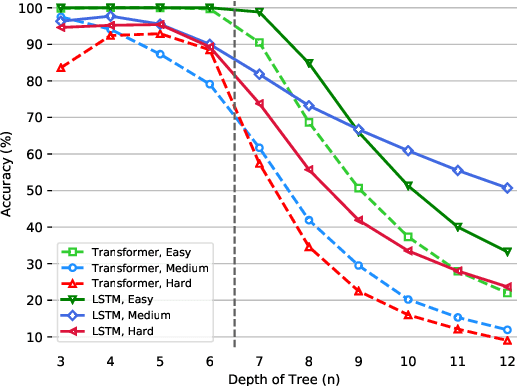
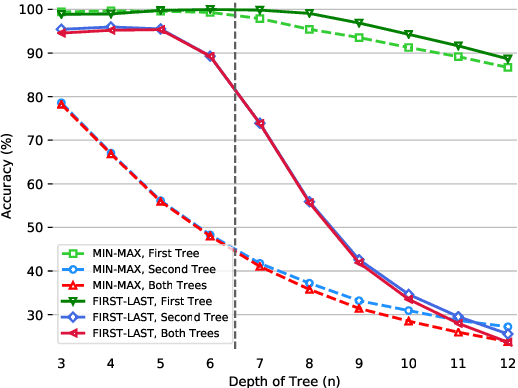
The ability to reason with multiple hierarchical structures is an attractive and desirable property of sequential inductive biases for natural language processing. Do the state-of-the-art Transformers and LSTM architectures implicitly encode for these biases? To answer this, we propose ORCHARD, a diagnostic dataset for systematically evaluating hierarchical reasoning in state-of-the-art neural sequence models. While there have been prior evaluation frameworks such as ListOps or Logical Inference, our work presents a novel and more natural setting where our models learn to reason with multiple explicit hierarchical structures instead of only one, i.e., requiring the ability to do both long-term sequence memorizing, relational reasoning while reasoning with hierarchical structure. Consequently, backed by a set of rigorous experiments, we show that (1) Transformer and LSTM models surprisingly fail in systematic generalization, and (2) with increased references between hierarchies, Transformer performs no better than random.
FastTrees: Parallel Latent Tree-Induction for Faster Sequence Encoding
Nov 28, 2021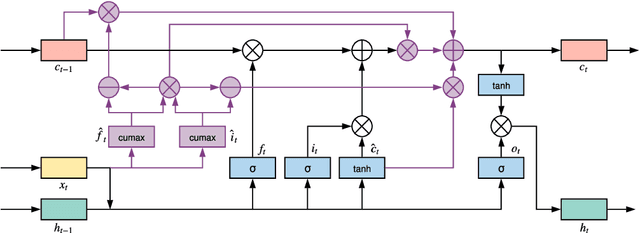
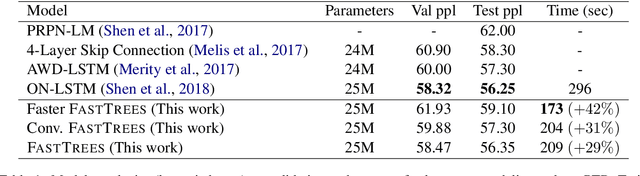
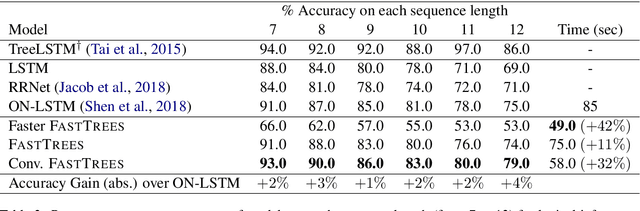
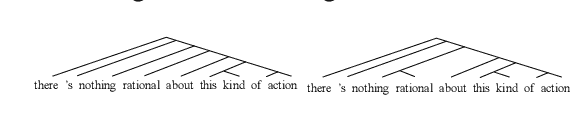
Inducing latent tree structures from sequential data is an emerging trend in the NLP research landscape today, largely popularized by recent methods such as Gumbel LSTM and Ordered Neurons (ON-LSTM). This paper proposes FASTTREES, a new general purpose neural module for fast sequence encoding. Unlike most previous works that consider recurrence to be necessary for tree induction, our work explores the notion of parallel tree induction, i.e., imbuing our model with hierarchical inductive biases in a parallelizable, non-autoregressive fashion. To this end, our proposed FASTTREES achieves competitive or superior performance to ON-LSTM on four well-established sequence modeling tasks, i.e., language modeling, logical inference, sentiment analysis and natural language inference. Moreover, we show that the FASTTREES module can be applied to enhance Transformer models, achieving performance gains on three sequence transduction tasks (machine translation, subject-verb agreement and mathematical language understanding), paving the way for modular tree induction modules. Overall, we outperform existing state-of-the-art models on logical inference tasks by +4% and mathematical language understanding by +8%.