 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance-Guided LLM Knowledge Distillation for Efficient Text Classification at Scale
Nov 07, 2024

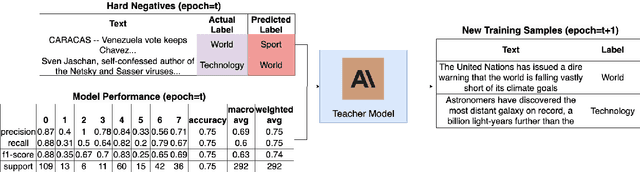
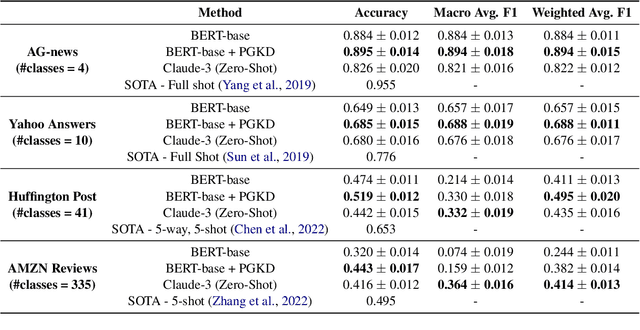
Large Language Models (LLMs) face significant challenges at inference time due to their high computational demands. To address this, we present Performance-Guided Knowledge Distillation (PGKD), a cost-effective and high-throughput solution for production text classification applications. PGKD utilizes teacher-student Knowledge Distillation to distill the knowledge of LLMs into smaller, task-specific models. PGKD establishes an active learning routine between the student model and the LLM; the LLM continuously generates new training data leveraging hard-negative mining, student model validation performance, and early-stopping protocols to inform the data generation. By employing a cyclical, performance-aware approach tailored for highly multi-class, sparsely annotated datasets prevalent in industrial text classification, PGKD effectively addresses training challenges and outperforms traditional BERT-base models and other knowledge distillation methods on several multi-class classification datasets. Additionally, cost and latency benchmarking reveals that models fine-tuned with PGKD are up to 130X faster and 25X less expensive than LLMs for inference on the same classification task. While PGKD is showcased for text classification tasks, its versatile framework can be extended to any LLM distillation task, including language generation, making it a powerful tool for optimizing performance across a wide range of AI applications.
Frustrated Random Walks: A Fast Method to Compute Node Distances on Hypergraphs
Jan 23, 2024A hypergraph is a generalization of a graph that arises naturally when attribute-sharing among entities is considered. Although a hypergraph can be converted into a graph by expanding its hyperedges into fully connected subgraphs, going the reverse way is computationally complex and NP-complete. We therefore hypothesize that a hypergraph contains more information than a graph. In addition, it is more convenient to manipulate a hypergraph directly, rather than expand it into a graph. An open problem in hypergraphs is how to accurately and efficiently calculate their node distances. Estimating node distances enables us to find a node's nearest neighbors, and perform label propagation on hypergraphs using a K-nearest neighbors (KNN) approach. In this paper, we propose a novel approach based on random walks to achieve label propagation on hypergraphs. We estimate node distances as the expected hitting times of random walks. We note that simple random walks (SRW) cannot accurately describe highly complex real-world hypergraphs, which motivates us to introduce frustrated random walks (FRW) to better describe them. We further benchmark our method against DeepWalk, and show that while the latter can achieve comparable results, FRW has a distinct computational advantage in cases where the number of targets is fairly small. For such cases, we show that FRW runs in significantly shorter time than DeepWalk. Finally, we analyze the time complexity of our method, and show that for large and sparse hypergraphs, the complexity is approximately linear, rendering it superior to the DeepWalk alternative.