 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Challenges of Evaluating LLM Applications: An Analysis of Automated, Human, and LLM-Based Approaches
Jun 05, 2024



Chatbots have been an interesting application of natural language generation since its inception. With novel transformer based Generative AI methods, building chatbots have become trivial. Chatbots which are targeted at specific domains such as medicine, psychology, and general information retrieval are implemented rapidly. This, however, should not distract from the need to evaluate the chatbot responses. Especially because the natural language generation community does not entirely agree upon how to effectively evaluate such applications. With this work we discuss the issue further with the increasingly popular LLM based evaluations and how they correlate with human evaluations. Additionally, we introduce a comprehensive factored evaluation mechanism that can be utilized in conjunction with both human and LLM-based evaluations. We present the results of an experimental evaluation conducted using this scheme in one of our chatbot implementations, and subsequently compare automated, traditional human evaluation, factored human evaluation, and factored LLM evaluation. Results show that factor based evaluation produces better insights on which aspects need to be improved in LLM applications and further strengthens the argument to use human evaluation in critical spaces where main functionality is not direct retrieval.
POSLAN: Disentangling Chat with Positional and Language encoded Post Embeddings
Jul 07, 2021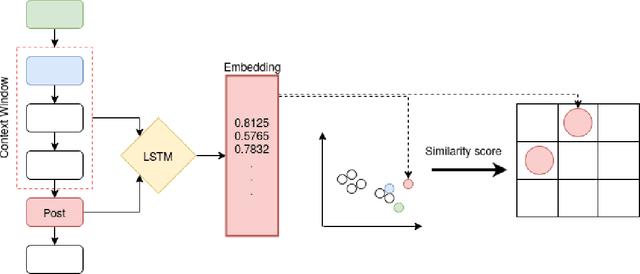

Most online message threads inherently will be cluttered and any new user or an existing user visiting after a hiatus will have a difficult time understanding whats being discussed in the thread. Similarly cluttered responses in a message thread makes analyzing the messages a difficult problem. The need for disentangling the clutter is much higher when the platform where the discussion is taking place does not provide functions to retrieve reply relations of the messages. This introduces an interesting problem to which \cite{wang2011learning} phrases as a structural learning problem. We create vector embeddings for posts in a thread so that it captures both linguistic and positional features in relation to a context of where a given message is in. Using these embeddings for posts we compute a similarity based connectivity matrix which then converted into a graph. After employing a pruning mechanisms the resultant graph can be used to discover the reply relation for the posts in the thread. The process of discovering or disentangling chat is kept as an unsupervised mechanism. We present our experimental results on a data set obtained from Telegram with limited meta data.