 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating into Free Word Order Languages
Apr 29, 1996

In this paper, I discuss machine translation of English text into Turkish, a relatively ``free'' word order language. I present algorithms that determine the topic and the focus of each target sentence (using salience (Centering Theory), old vs. new information, and contrastiveness in the discourse model) in order to generate the contextually appropriate word orders in the target language.
Integrating "Free" Word Order Syntax and Information Structure
Feb 15, 1995

This paper describes a combinatory categorial formalism called Multiset-CCG that can capture the syntax and interpretation of ``free'' word order in languages such as Turkish. The formalism compositionally derives the predicate-argument structure and the information structure (e.g. topic, focus) of a sentence in parallel, and uniformly handles word order variation among the arguments and adjuncts within a clause, as well as in complex clauses and across clause boundaries.
Generating Context-Appropriate Word Orders in Turkish
Jul 20, 1994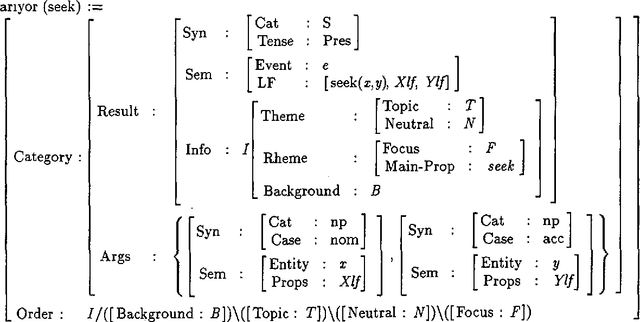



Turkish has considerably freer word order than English. The interpretations of different word orders in Turkish rely on information that describes how a sentence relates to its discourse context. To capture the syntactic features of a free word order language, I present an adaptation of Combinatory Categorial Grammars called {}-CCGs (set-CCGs). In {}-CCGs, a verb's subcategorization requirements are relaxed so that it requires a set of arguments without specifying their linear order. I integrate a level of information structure, representing pragmatic functions such as topic and focus, with {}-CCGs to allow certain pragmatic distinctions in meaning to influence the word order of a sentence in a compositional way. Finally, I discuss how this strategy is used within an implemented generation system which produces Turkish sentences with context-appropriate word orders in a simple database query task.