 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Conducting Advanced Text Analytics Information Systems Research
Dec 27, 2023



The exponential growth of digital content has generated massive textual datasets, necessitating advanced analytical approaches. Large Language Models (LLMs) have emerged as tools capable of processing and extracting insights from massive unstructured textual datasets. However, how to leverage LLMs for text-based Information Systems (IS) research is currently unclear. To assist IS research in understanding how to operationalize LLMs, we propose a Text Analytics for Information Systems Research (TAISR) framework. Our proposed framework provides detailed recommendations grounded in IS and LLM literature on how to conduct meaningful text-based IS research. We conducted three case studies in business intelligence using our TAISR framework to demonstrate its application across several IS research contexts. We also outline potential challenges and limitations in adopting LLMs for IS. By offering a systematic approach and evidence of its utility, our TAISR framework contributes to future IS research streams looking to incorporate powerful LLMs for text analytics.
Predicting Organizational Cybersecurity Risk: A Deep Learning Approach
Dec 26, 2020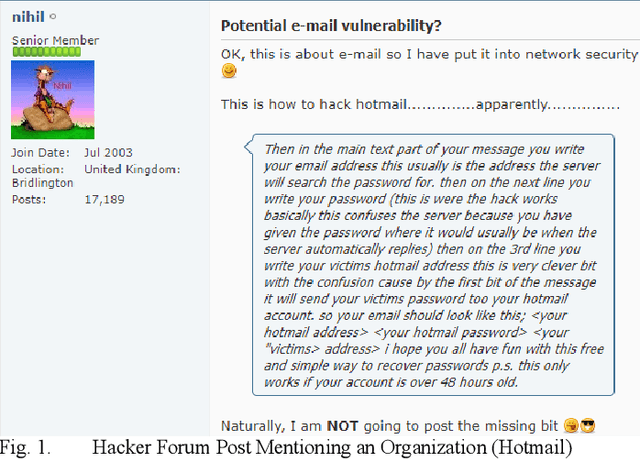

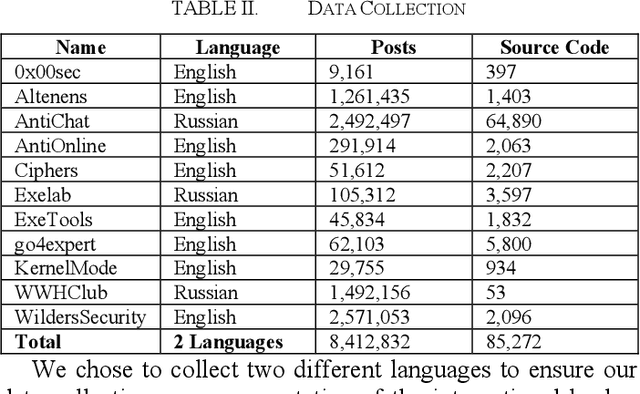

Cyberattacks conducted by malicious hackers cause irreparable damage to organizations, governments, and individuals every year. Hackers use exploits found on hacker forums to carry out complex cyberattacks, making exploration of these forums vital. We propose a hacker forum entity recognition framework (HackER) to identify exploits and the entities that the exploits target. HackER then uses a bidirectional long short-term memory model (BiLSTM) to create a predictive model for what companies will be targeted by exploits. The results of the algorithm will be evaluated using a manually labeled gold-standard test dataset, using accuracy, precision, recall, and F1-score as metrics. We choose to compare our model against state of the art classical machine learning and deep learning benchmark models. Results show that our proposed HackER BiLSTM model outperforms all classical machine learning and deep learning models in F1-score (79.71%). These results are statistically significant at 0.05 or lower for all benchmarks except LSTM. The results of preliminary work suggest our model can help key cybersecurity stakeholders (e.g., analysts, researchers, educators) identify what type of business an exploit is targeting.