 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCut-Paste Consistency Learning for Semi-Supervised Lesion Segmentation
Oct 01, 2022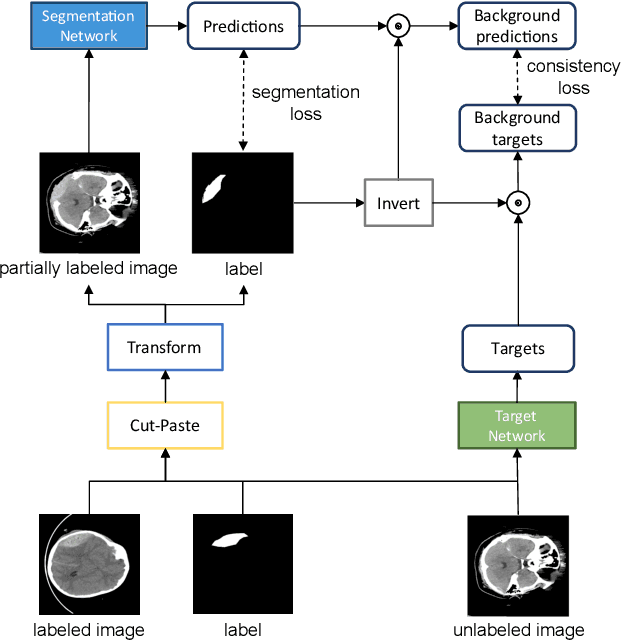
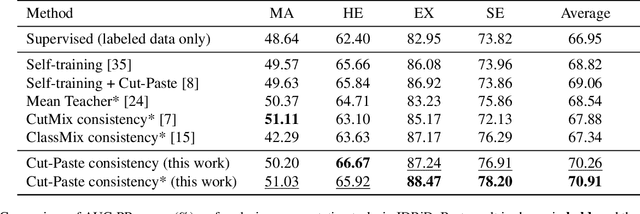
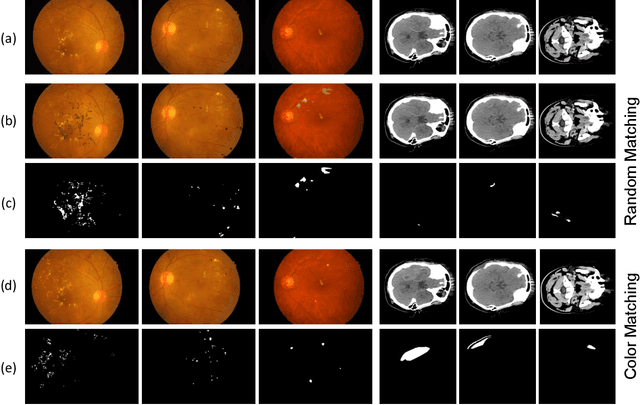
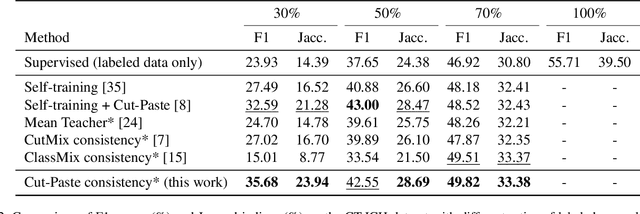
Semi-supervised learning has the potential to improve the data-efficiency of training data-hungry deep neural networks, which is especially important for medical image analysis tasks where labeled data is scarce. In this work, we present a simple semi-supervised learning method for lesion segmentation tasks based on the ideas of cut-paste augmentation and consistency regularization. By exploiting the mask information available in the labeled data, we synthesize partially labeled samples from the unlabeled images so that the usual supervised learning objective (e.g., binary cross entropy) can be applied. Additionally, we introduce a background consistency term to regularize the training on the unlabeled background regions of the synthetic images. We empirically verify the effectiveness of the proposed method on two public lesion segmentation datasets, including an eye fundus photograph dataset and a brain CT scan dataset. The experiment results indicate that our method achieves consistent and superior performance over other self-training and consistency-based methods without introducing sophisticated network components.
Semi-weakly Supervised Contrastive Representation Learning for Retinal Fundus Images
Aug 04, 2021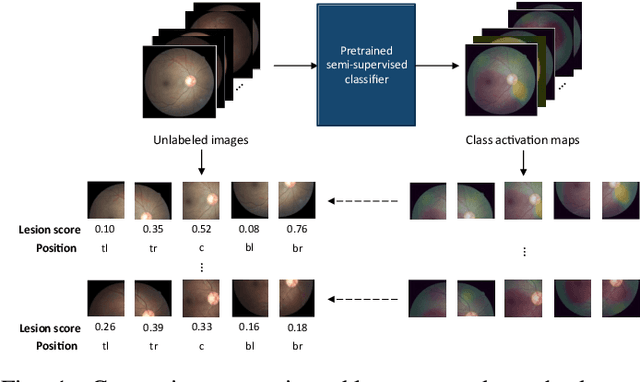
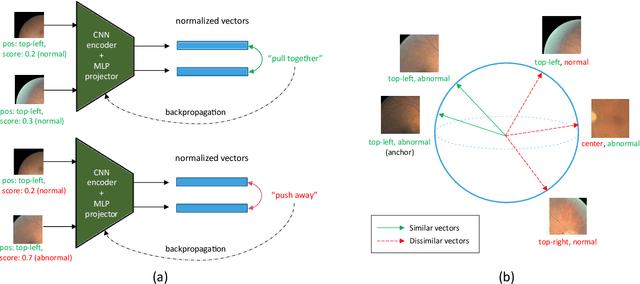
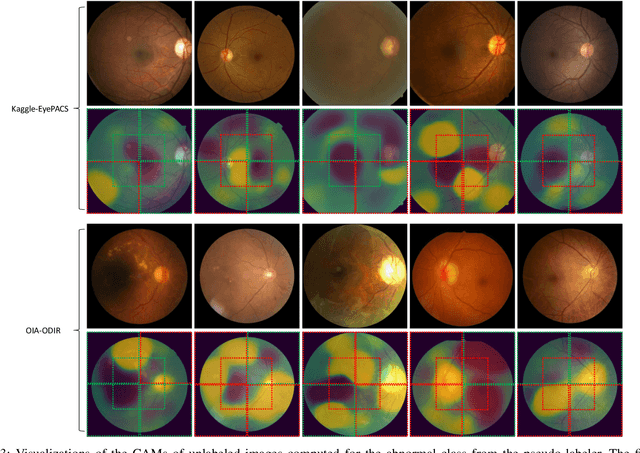
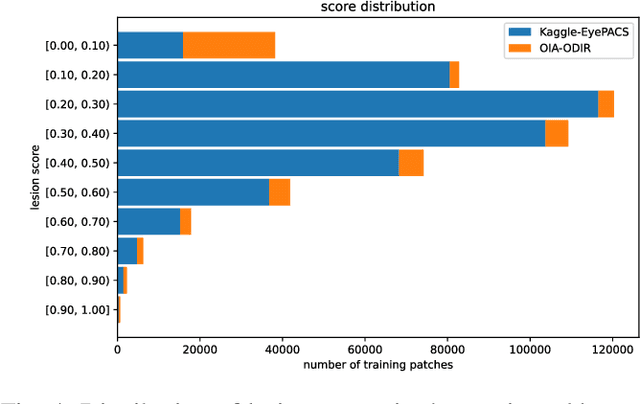
We explore the value of weak labels in learning transferable representations for medical images. Compared to hand-labeled datasets, weak or inexact labels can be acquired in large quantities at significantly lower cost and can provide useful training signals for data-hungry models such as deep neural networks. We consider weak labels in the form of pseudo-labels and propose a semi-weakly supervised contrastive learning (SWCL) framework for representation learning using semi-weakly annotated images. Specifically, we train a semi-supervised model to propagate labels from a small dataset consisting of diverse image-level annotations to a large unlabeled dataset. Using the propagated labels, we generate a patch-level dataset for pretraining and formulate a multi-label contrastive learning objective to capture position-specific features encoded in each patch. We empirically validate the transfer learning performance of SWCL on seven public retinal fundus datasets, covering three disease classification tasks and two anatomical structure segmentation tasks. Our experiment results suggest that, under very low data regime, large-scale ImageNet pretraining on improved architecture remains a very strong baseline, and recently proposed self-supervised methods falter in segmentation tasks, possibly due to the strong invariant constraint imposed. Our method surpasses all prior self-supervised methods and standard cross-entropy training, while closing the gaps with ImageNet pretraining.