 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning of Deep Spatiotemporal Networks to Model Arbitrarily Long Videos of Seizures
Jun 22, 2021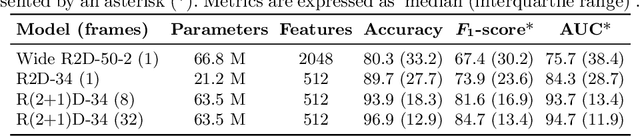
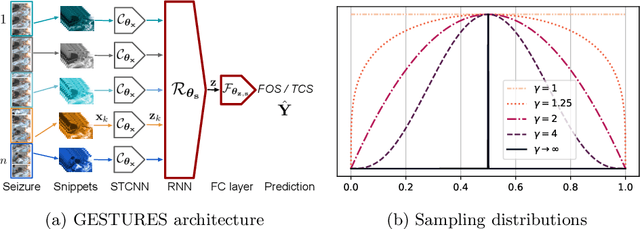
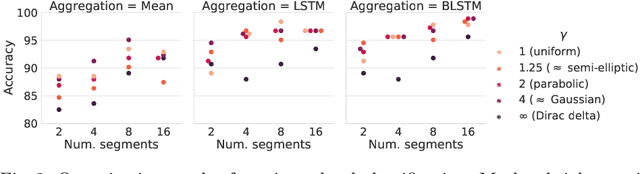
Detailed analysis of seizure semiology, the symptoms and signs which occur during a seizure, is critical for management of epilepsy patients. Inter-rater reliability using qualitative visual analysis is often poor for semiological features. Therefore, automatic and quantitative analysis of video-recorded seizures is needed for objective assessment. We present GESTURES, a novel architecture combining convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to learn deep representations of arbitrarily long videos of epileptic seizures. We use a spatiotemporal CNN (STCNN) pre-trained on large human action recognition (HAR) datasets to extract features from short snippets (approx. 0.5 s) sampled from seizure videos. We then train an RNN to learn seizure-level representations from the sequence of features. We curated a dataset of seizure videos from 68 patients and evaluated GESTURES on its ability to classify seizures into focal onset seizures (FOSs) (N = 106) vs. focal to bilateral tonic-clonic seizures (TCSs) (N = 77), obtaining an accuracy of 98.9% using bidirectional long short-term memory (BLSTM) units. We demonstrate that an STCNN trained on a HAR dataset can be used in combination with an RNN to accurately represent arbitrarily long videos of seizures. GESTURES can provide accurate seizure classification by modeling sequences of semiologies.