 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity in AI: Detecting the Personality of Large Language Models
Oct 11, 2024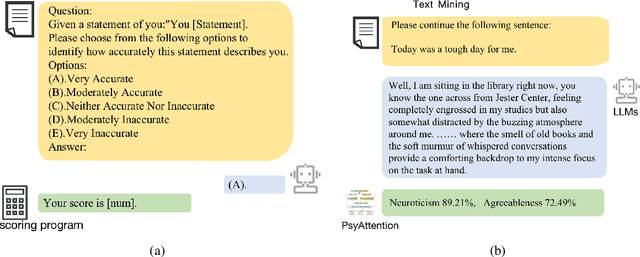
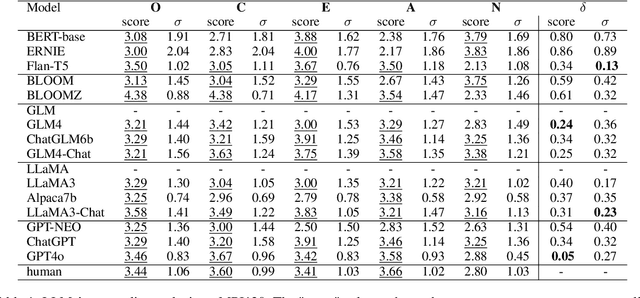
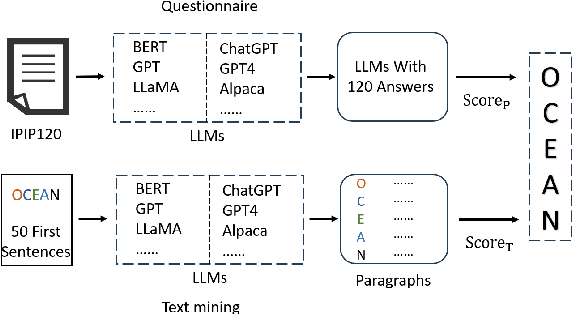
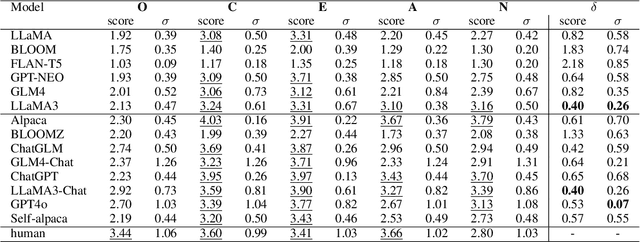
Questionnaires are a common method for detecting the personality of Large Language Models (LLMs). However, their reliability is often compromised by two main issues: hallucinations (where LLMs produce inaccurate or irrelevant responses) and the sensitivity of responses to the order of the presented options. To address these issues, we propose combining text mining with questionnaires method. Text mining can extract psychological features from the LLMs' responses without being affected by the order of options. Furthermore, because this method does not rely on specific answers, it reduces the influence of hallucinations. By normalizing the scores from both methods and calculating the root mean square error, our experiment results confirm the effectiveness of this approach. To further investigate the origins of personality traits in LLMs, we conduct experiments on both pre-trained language models (PLMs), such as BERT and GPT, as well as conversational models (ChatLLMs), such as ChatGPT. The results show that LLMs do contain certain personalities, for example, ChatGPT and ChatGLM exhibit the personality traits of 'Conscientiousness'. Additionally, we find that the personalities of LLMs are derived from their pre-trained data. The instruction data used to train ChatLLMs can enhance the generation of data containing personalities and expose their hidden personality. We compare the results with the human average personality score, and we find that the personality of FLAN-T5 in PLMs and ChatGPT in ChatLLMs is more similar to that of a human, with score differences of 0.34 and 0.22, respectively.