 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModified SMOTE Using Mutual Information and Different Sorts of Entropies
Mar 29, 2018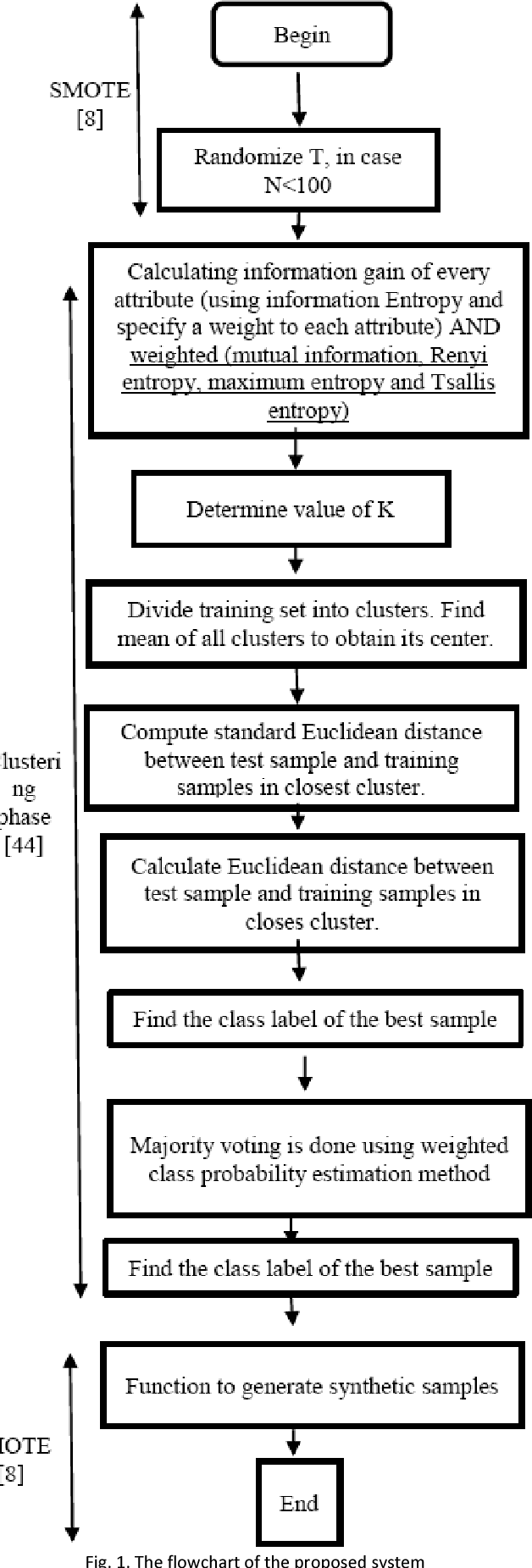
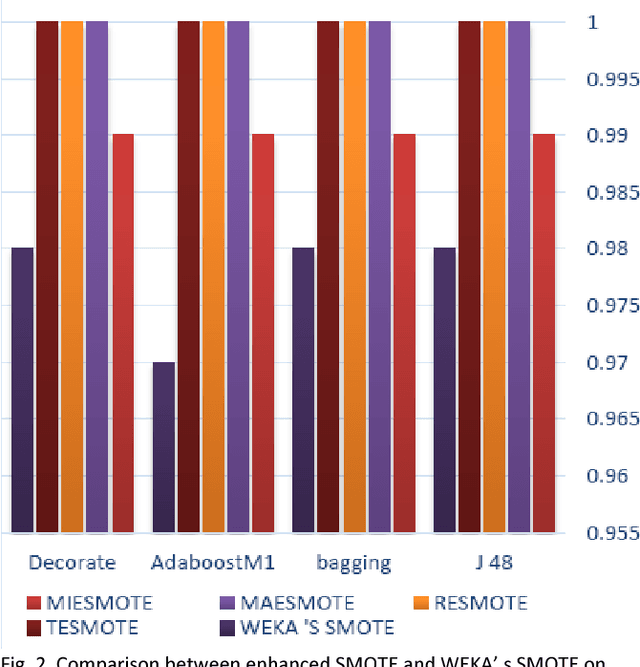
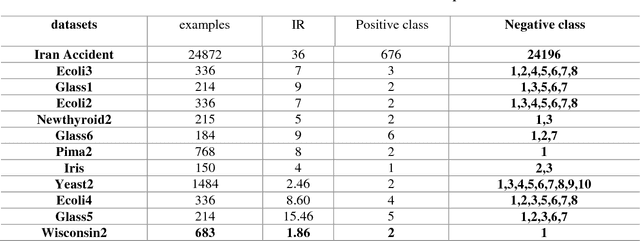
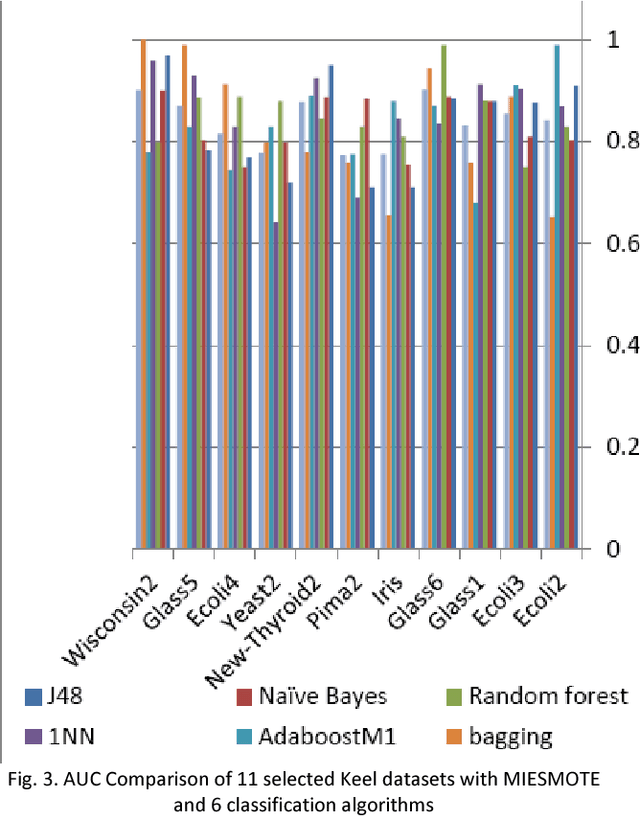
SMOTE is one of the oversampling techniques for balancing the datasets and it is considered as a pre-processing step in learning algorithms. In this paper, four new enhanced SMOTE are proposed that include an improved version of KNN in which the attribute weights are defined by mutual information firstly and then they are replaced by maximum entropy, Renyi entropy and Tsallis entropy. These four pre-processing methods are combined with 1NN and J48 classifiers and their performance are compared with the previous methods on 11 imbalanced datasets from KEEL repository. The results show that these pre-processing methods improves the accuracy compared with the previous stablished works. In addition, as a case study, the first pre-processing method is applied on transportation data of Tehran-Bazargan Highway in Iran with IR equal to 36.