 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLOv4: A Breakthrough in Real-Time Object Detection
Feb 06, 2025


YOLOv4 achieved the best performance on the COCO dataset by combining advanced techniques for regression (bounding box positioning) and classification (object class identification) using the Darknet framework. To enhance accuracy and adaptability, it employs Cross mini-Batch Normalization, Cross-Stage-Partial-connections, Self-Adversarial-Training, and Weighted-Residual-Connections, as well as CIoU loss, Mosaic data augmentation, and DropBlock regularization. With Mosaic augmentation and multi-resolution training, YOLOv4 achieves superior detection in diverse scenarios, attaining 43.5\% AP (in contrast, 65.7\% AP50) on a Tesla V100 at ~65 frames per second, ensuring efficiency, affordability, and adaptability for real-world environments.
Performance of YOLOv7 in Kitchen Safety While Handling Knife
Jan 09, 2025



Safe knife practices in the kitchen significantly reduce the risk of cuts, injuries, and serious accidents during food preparation. Using YOLOv7, an advanced object detection model, this study focuses on identifying safety risks during knife handling, particularly improper finger placement and blade contact with hand. The model's performance was evaluated using metrics such as precision, recall, mAP50, and mAP50-95. The results demonstrate that YOLOv7 achieved its best performance at epoch 31, with a mAP50-95 score of 0.7879, precision of 0.9063, and recall of 0.7503. These findings highlight YOLOv7's potential to accurately detect knife-related hazards, promoting the development of improved kitchen safety.
What is YOLOv6? A Deep Insight into the Object Detection Model
Dec 17, 2024



This work explores the YOLOv6 object detection model in depth, concentrating on its design framework, optimization techniques, and detection capabilities. YOLOv6's core elements consist of the EfficientRep Backbone for robust feature extraction and the Rep-PAN Neck for seamless feature aggregation, ensuring high-performance object detection. Evaluated on the COCO dataset, YOLOv6-N achieves 37.5\% AP at 1187 FPS on an NVIDIA Tesla T4 GPU. YOLOv6-S reaches 45.0\% AP at 484 FPS, outperforming models like PPYOLOE-S, YOLOv5-S, YOLOX-S, and YOLOv8-S in the same class. Moreover, YOLOv6-M and YOLOv6-L also show better accuracy (50.0\% and 52.8\%) while maintaining comparable inference speeds to other detectors. With an upgraded backbone and neck structure, YOLOv6-L6 delivers cutting-edge accuracy in real-time.
Comparing YOLOv5 Variants for Vehicle Detection: A Performance Analysis
Aug 22, 2024Vehicle detection is an important task in the management of traffic and automatic vehicles. This study provides a comparative analysis of five YOLOv5 variants, YOLOv5n6s, YOLOv5s6s, YOLOv5m6s, YOLOv5l6s, and YOLOv5x6s, for vehicle detection in various environments. The research focuses on evaluating the effectiveness of these models in detecting different types of vehicles, such as Car, Bus, Truck, Bicycle, and Motorcycle, under varying conditions including lighting, occlusion, and weather. Performance metrics such as precision, recall, F1-score, and mean Average Precision are utilized to assess the accuracy and reliability of each model. YOLOv5n6s demonstrated a strong balance between precision and recall, particularly in detecting Cars. YOLOv5s6s and YOLOv5m6s showed improvements in recall, enhancing their ability to detect all relevant objects. YOLOv5l6s, with its larger capacity, provided robust performance, especially in detecting Cars, but not good with identifying Motorcycles and Bicycles. YOLOv5x6s was effective in recognizing Buses and Cars but faced challenges with Motorcycle class.
From SAM to SAM 2: Exploring Improvements in Meta's Segment Anything Model
Aug 12, 2024The Segment Anything Model (SAM), introduced to the computer vision community by Meta in April 2023, is a groundbreaking tool that allows automated segmentation of objects in images based on prompts such as text, clicks, or bounding boxes. SAM excels in zero-shot performance, segmenting unseen objects without additional training, stimulated by a large dataset of over one billion image masks. SAM 2 expands this functionality to video, leveraging memory from preceding and subsequent frames to generate accurate segmentation across entire videos, enabling near real-time performance. This comparison shows how SAM has evolved to meet the growing need for precise and efficient segmentation in various applications. The study suggests that future advancements in models like SAM will be crucial for improving computer vision technology.
A Comparative Analysis of YOLOv5, YOLOv8, and YOLOv10 in Kitchen Safety
Jul 30, 2024
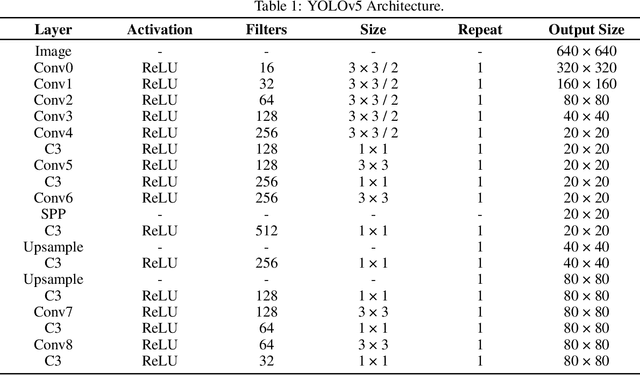
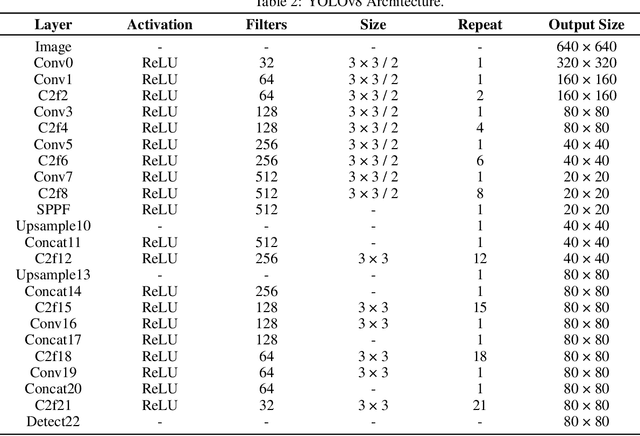
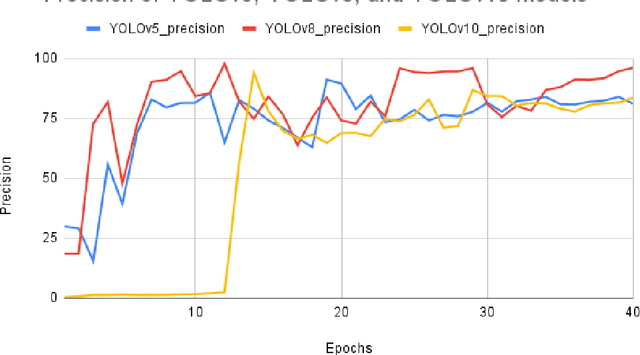
Knife safety in the kitchen is essential for preventing accidents or injuries with an emphasis on proper handling, maintenance, and storage methods. This research presents a comparative analysis of three YOLO models, YOLOv5, YOLOv8, and YOLOv10, to detect the hazards involved in handling knife, concentrating mainly on ensuring fingers are curled while holding items to be cut and that hands should only be in contact with knife handle avoiding the blade. Precision, recall, F-score, and normalized confusion matrix are used to evaluate the performance of the models. The results indicate that YOLOv5 performed better than the other two models in identifying the hazard of ensuring hands only touch the blade, while YOLOv8 excelled in detecting the hazard of curled fingers while holding items. YOLOv5 and YOLOv8 performed almost identically in recognizing classes such as hand, knife, and vegetable, whereas YOLOv5, YOLOv8, and YOLOv10 accurately identified the cutting board. This paper provides insights into the advantages and shortcomings of these models in real-world settings. Moreover, by detailing the optimization of YOLO architectures for safe knife handling, this study promotes the development of increased accuracy and efficiency in safety surveillance systems.