 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering mesoscopic descriptions of collective movement with neural stochastic modelling
Mar 17, 2023



Collective motion is an ubiquitous phenomenon in nature, inspiring engineers, physicists and mathematicians to develop mathematical models and bio-inspired designs. Collective motion at small to medium group sizes ($\sim$10-1000 individuals, also called the `mesoscale'), can show nontrivial features due to stochasticity. Therefore, characterizing both the deterministic and stochastic aspects of the dynamics is crucial in the study of mesoscale collective phenomena. Here, we use a physics-inspired, neural-network based approach to characterize the stochastic group dynamics of interacting individuals, through a stochastic differential equation (SDE) that governs the collective dynamics of the group. We apply this technique on both synthetic and real-world datasets, and identify the deterministic and stochastic aspects of the dynamics using drift and diffusion fields, enabling us to make novel inferences about the nature of order in these systems.
PyDaddy: A Python package for discovering stochastic dynamical equations from timeseries data
May 05, 2022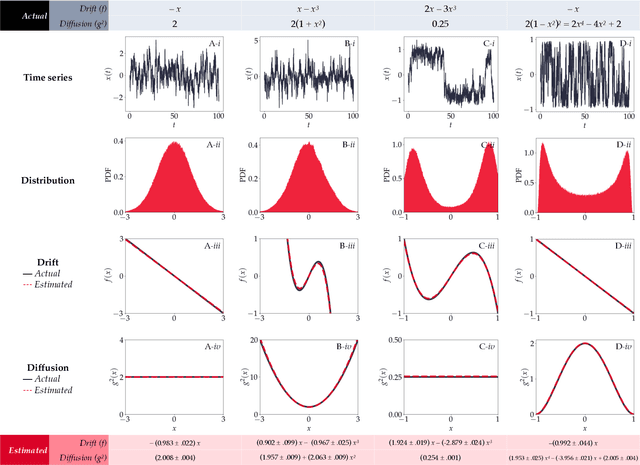
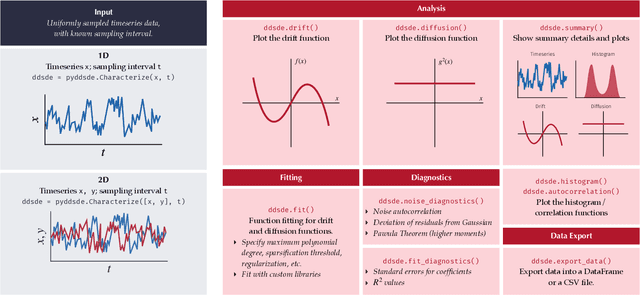
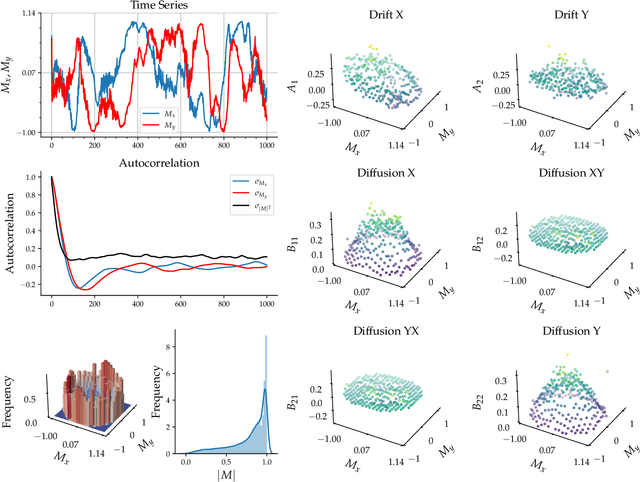

Most real-world ecological dynamics, ranging from ecosystem dynamics to collective animal movement, are inherently stochastic in nature. Stochastic differential equations (SDEs) are a popular modelling framework to model dynamics with intrinsic randomness. Here, we focus on the inverse question: If one has empirically measured time-series data from some system of interest, is it possible to discover the SDE model that best describes the data. Here, we present PyDaddy (PYthon library for DAta Driven DYnamics), a toolbox to construct and analyze interpretable SDE models based on time-series data. We combine traditional approaches for data-driven SDE reconstruction with an equation learning approach, to derive symbolic equations governing the stochastic dynamics. The toolkit is presented as an open-source Python library, and consists of tools to construct and analyze SDEs. Functionality is included for visual examination of the stochastic structure of the data, guided extraction of the functional form of the SDE, and diagnosis and debugging of the underlying assumptions and the extracted model. Using simulated time-series datasets, exhibiting a wide range of dynamics, we show that PyDaddy is able to correctly identify underlying SDE models. We demonstrate the applicability of the toolkit to real-world data using a previously published movement data of a fish school. Starting from the time-series of the observed polarization of the school, pyDaddy readily discovers the SDE model governing the dynamics of group polarization. The model recovered by PyDaddy is consistent with the previous study. In summary, stochastic and noise-induced effects are central to the dynamics of many biological systems. In this context, we present an easy-to-use package to reconstruct SDEs from timeseries data.
Observing a group to infer individual characteristics
Oct 12, 2021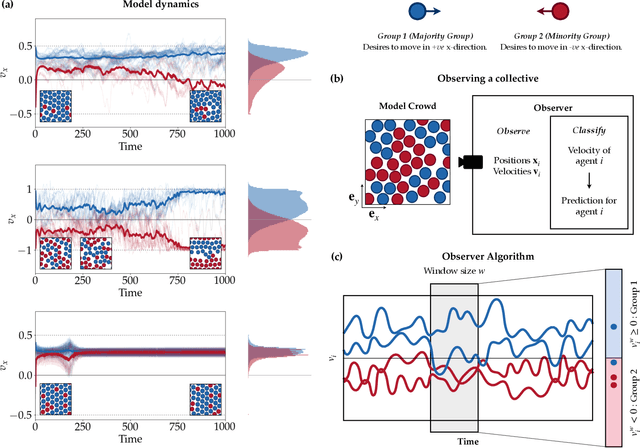
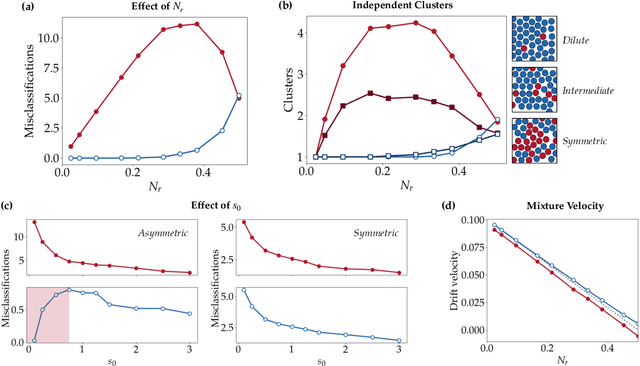
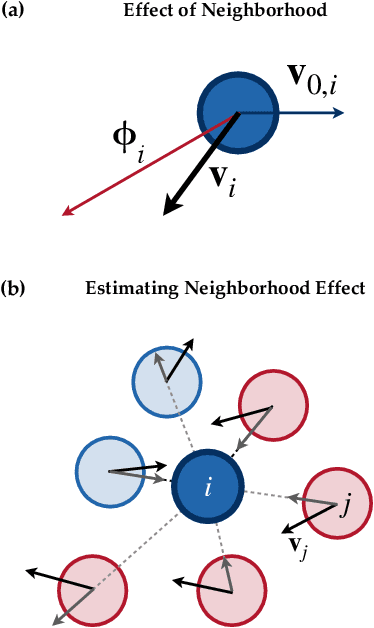

In the study of collective motion, it is common practice to collect movement information at the level of the group to infer the characteristics of the individual agents and their interactions. However, it is not clear whether one can always correctly infer individual characteristics from movement data of the collective. We investigate this question in the context of a composite crowd with two groups of agents, each with its own desired direction of motion. A simple observer attempts to classify an agent into its group based on its movement information. However, collective effects such as collisions, entrainment of agents, formation of lanes and clusters, etc. render the classification problem non-trivial, and lead to misclassifications. Based on our understanding of these effects, we propose a new observer algorithm that infers, based only on observed movement information, how the local neighborhood aids or hinders agent movement. Unlike a traditional supervised learning approach, this algorithm is based on physical insights and scaling arguments, and does not rely on training-data. This new observer improves classification performance and is able to differentiate agents belonging to different groups even when their motion is identical. Data-agnostic approaches like this have relevance to a large class of real-world problems where clean, labeled data is difficult to obtain, and is a step towards hybrid approaches that integrate both data and domain knowledge.