 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Segmentation of Anaemic RBCs Using Multilevel Deep Convolutional Encoder-Decoder Network
Feb 09, 2022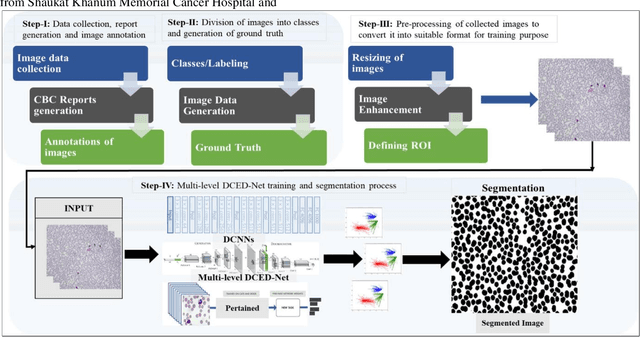

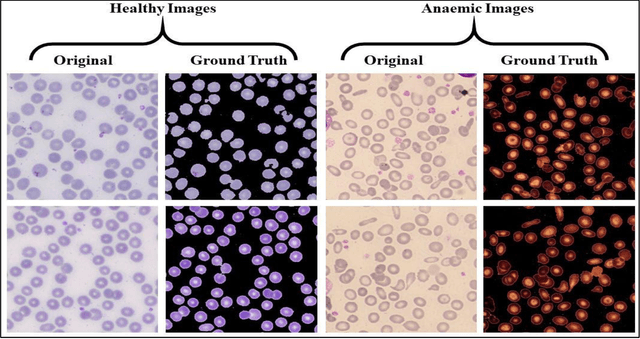
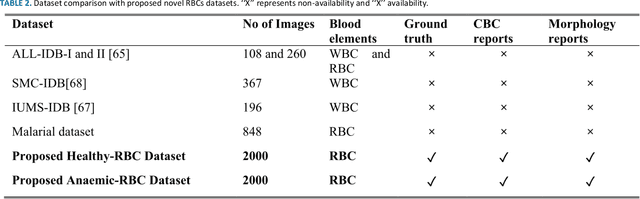
Pixel-level analysis of blood images plays a pivotal role in diagnosing blood-related diseases, especially Anaemia. These analyses mainly rely on an accurate diagnosis of morphological deformities like shape, size, and precise pixel counting. In traditional segmentation approaches, instance or object-based approaches have been adopted that are not feasible for pixel-level analysis. The convolutional neural network (CNN) model required a large dataset with detailed pixel-level information for the semantic segmentation of red blood cells in the deep learning domain. In current research work, we address these problems by proposing a multi-level deep convolutional encoder-decoder network along with two state-of-the-art healthy and Anaemic-RBC datasets. The proposed multi-level CNN model preserved pixel-level semantic information extracted in one layer and then passed to the next layer to choose relevant features. This phenomenon helps to precise pixel-level counting of healthy and anaemic-RBC elements along with morphological analysis. For experimental purposes, we proposed two state-of-the-art RBC datasets, i.e., Healthy-RBCs and Anaemic-RBCs dataset. Each dataset contains 1000 images, ground truth masks, relevant, complete blood count (CBC), and morphology reports for performance evaluation. The proposed model results were evaluated using crossmatch analysis with ground truth mask by finding IoU, individual training, validation, testing accuracies, and global accuracies using a 05-fold training procedure. This model got training, validation, and testing accuracies as 0.9856, 0.9760, and 0.9720 on the Healthy-RBC dataset and 0.9736, 0.9696, and 0.9591 on an Anaemic-RBC dataset. The IoU and BFScore of the proposed model were 0.9311, 0.9138, and 0.9032, 0.8978 on healthy and anaemic datasets, respectively.
Robust Method for Semantic Segmentation of Whole-Slide Blood Cell Microscopic Image
Jan 28, 2020

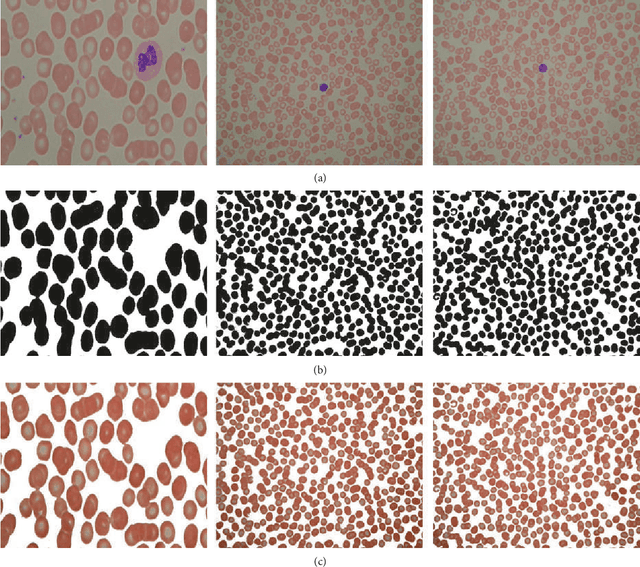

Previous works on segmentation of SEM (scanning electron microscope) blood cell image ignore the semantic segmentation approach of whole-slide blood cell segmentation. In the proposed work, we address the problem of whole-slide blood cell segmentation using the semantic segmentation approach. We design a novel convolutional encoder-decoder framework along with VGG-16 as the pixel-level feature extraction model. -e proposed framework comprises 3 main steps: First, all the original images along with manually generated ground truth masks of each blood cell type are passed through the preprocessing stage. In the preprocessing stage, pixel-level labeling, RGB to grayscale conversion of masked image and pixel fusing, and unity mask generation are performed. After that, VGG16 is loaded into the system, which acts as a pretrained pixel-level feature extraction model. In the third step, the training process is initiated on the proposed model. We have evaluated our network performance on three evaluation metrics. We obtained outstanding results with respect to classwise, as well as global and mean accuracies. Our system achieved classwise accuracies of 97.45%, 93.34%, and 85.11% for RBCs, WBCs, and platelets, respectively, while global and mean accuracies remain 97.18% and 91.96%, respectively.
* 13 pages, 13 figures