 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Multi-source Active Learning for Natural Language Inference
Feb 14, 2023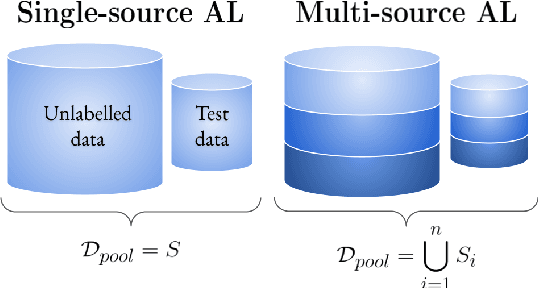
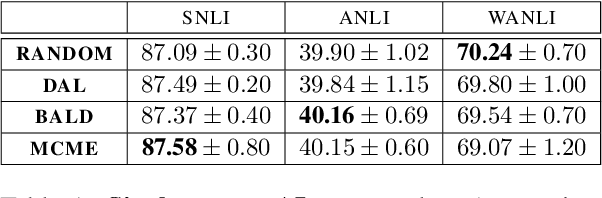
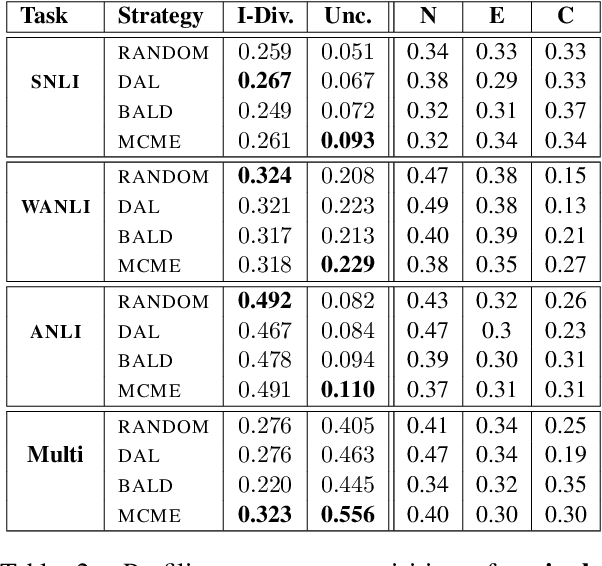
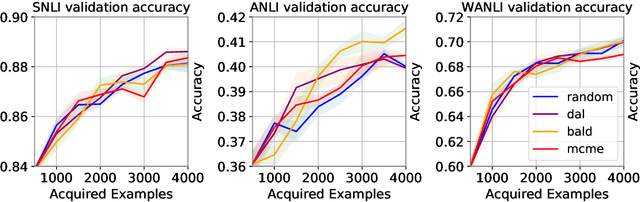
In recent years, active learning has been successfully applied to an array of NLP tasks. However, prior work often assumes that training and test data are drawn from the same distribution. This is problematic, as in real-life settings data may stem from several sources of varying relevance and quality. We show that four popular active learning schemes fail to outperform random selection when applied to unlabelled pools comprised of multiple data sources on the task of natural language inference. We reveal that uncertainty-based strategies perform poorly due to the acquisition of collective outliers, i.e., hard-to-learn instances that hamper learning and generalization. When outliers are removed, strategies are found to recover and outperform random baselines. In further analysis, we find that collective outliers vary in form between sources, and show that hard-to-learn data is not always categorically harmful. Lastly, we leverage dataset cartography to introduce difficulty-stratified testing and find that different strategies are affected differently by example learnability and difficulty.