 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Multi-label Classification with Frequent Label-set Mining and Association
Sep 22, 2021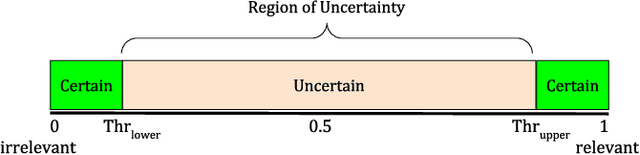
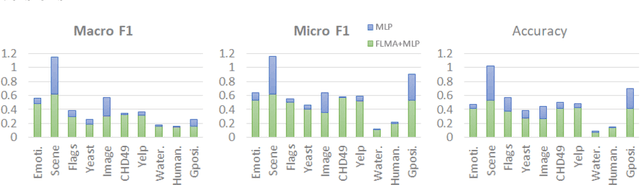
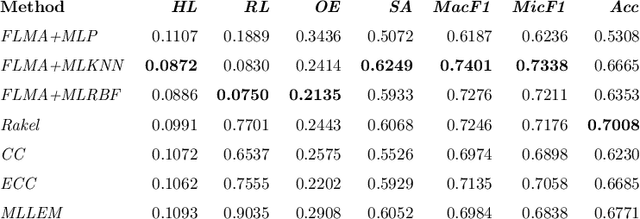
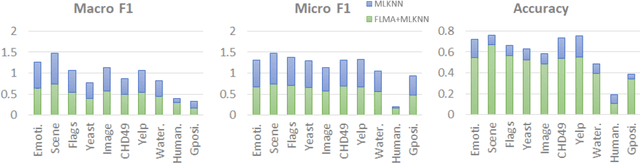
Multi-label (ML) data deals with multiple classes associated with individual samples at the same time. This leads to the co-occurrence of several classes repeatedly, which indicates some existing correlation among them. In this article, the correlation among classes has been explored to improve the classification performance of existing ML classifiers. A novel approach of frequent label-set mining has been proposed to extract these correlated classes from the label-sets of the data. Both co-presence (CP) and co-absence (CA) of classes have been taken into consideration. The rules mined from the ML data has been further used to incorporate class correlation information into existing ML classifiers. The soft scores generated by an ML classifier are modified through a novel approach using the CP-CA rules. A concept of certain and uncertain scores has been defined here, where the proposed method aims to improve the uncertain scores with the help of the certain scores and their corresponding CP-CA rules. This has been experimentally analysed on ten ML datasets for three ML existing classifiers which shows substantial improvement in their overall performance.
Integration of Autoencoder and Functional Link Artificial Neural Network for Multi-label Classification
Jul 21, 2021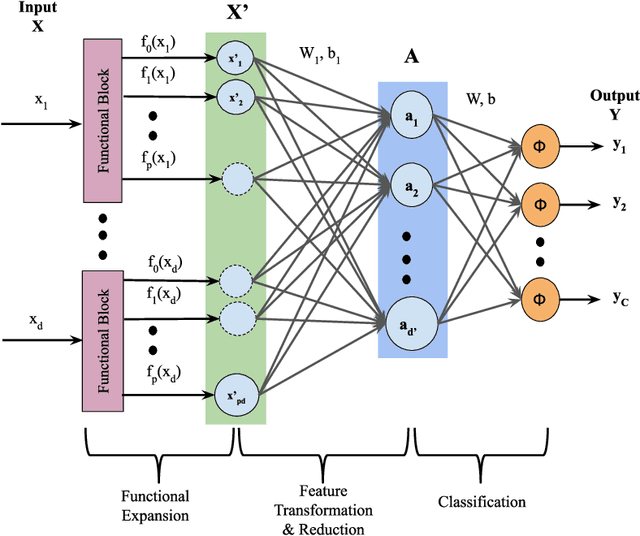
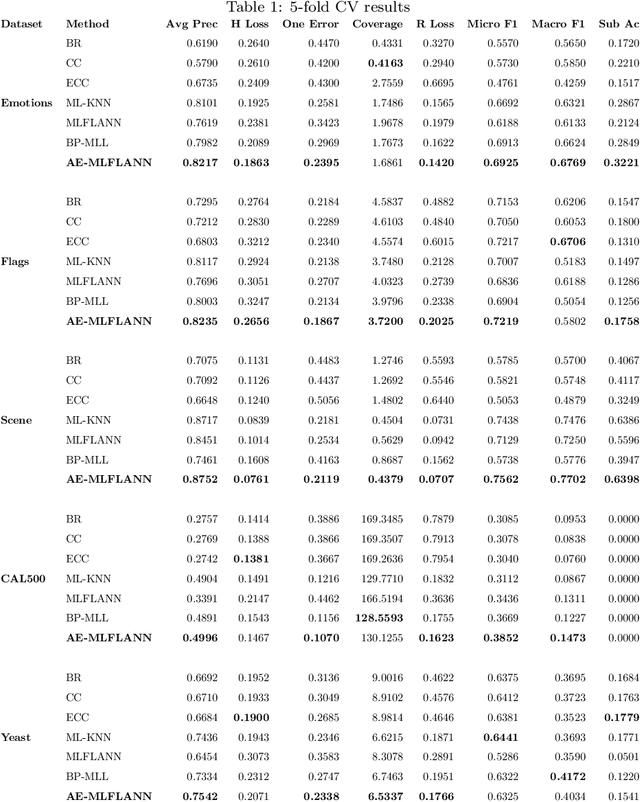
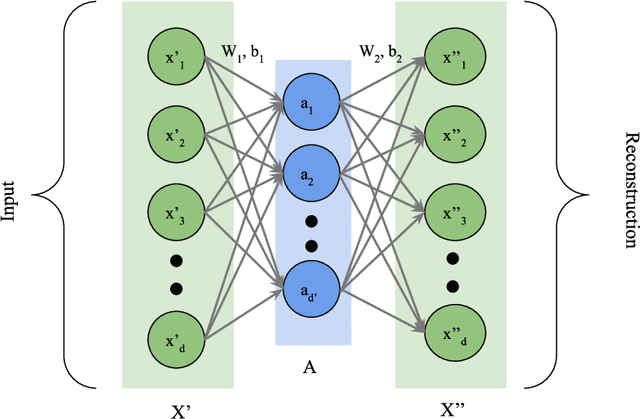

Multi-label (ML) classification is an actively researched topic currently, which deals with convoluted and overlapping boundaries that arise due to several labels being active for a particular data instance. We propose a classifier capable of extracting underlying features and introducing non-linearity to the data to handle the complex decision boundaries. A novel neural network model has been developed where the input features are subjected to two transformations adapted from multi-label functional link artificial neural network and autoencoders. First, a functional expansion of the original features are made using basis functions. This is followed by an autoencoder-aided transformation and reduction on the expanded features. This network is capable of improving separability for the multi-label data owing to the two-layer transformation while reducing the expanded feature space to a more manageable amount. This balances the input dimension which leads to a better classification performance even for a limited amount of data. The proposed network has been validated on five ML datasets which shows its superior performance in comparison with six well-established ML classifiers. Furthermore, a single-label variation of the proposed network has also been formulated simultaneously and tested on four relevant datasets against three existing classifiers to establish its effectiveness.