 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exponential Averaging Process with Strong Convergence Properties
May 15, 2025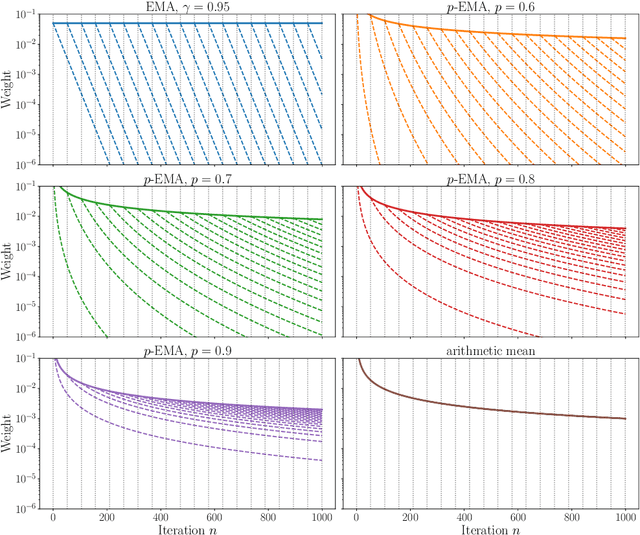
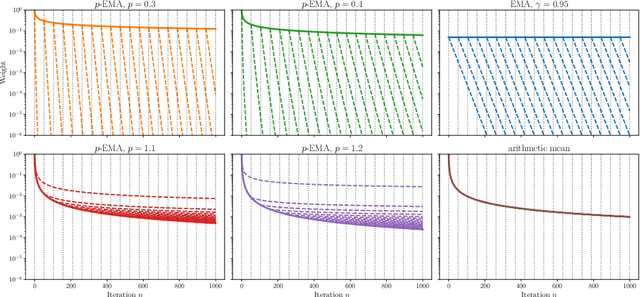
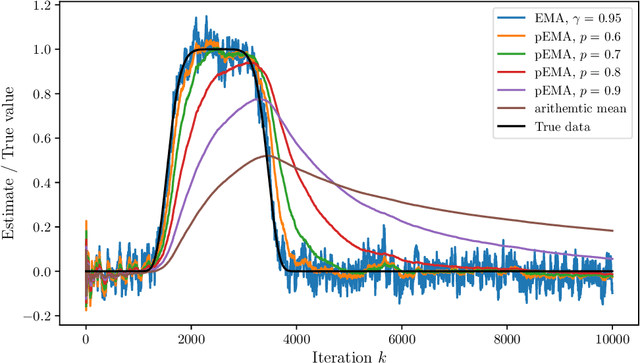

Averaging, or smoothing, is a fundamental approach to obtain stable, de-noised estimates from noisy observations. In certain scenarios, observations made along trajectories of random dynamical systems are of particular interest. One popular smoothing technique for such a scenario is exponential moving averaging (EMA), which assigns observations a weight that decreases exponentially in their age, thus giving younger observations a larger weight. However, EMA fails to enjoy strong stochastic convergence properties, which stems from the fact that the weight assigned to the youngest observation is constant over time, preventing the noise in the averaged quantity from decreasing to zero. In this work, we consider an adaptation to EMA, which we call $p$-EMA, where the weights assigned to the last observations decrease to zero at a subharmonic rate. We provide stochastic convergence guarantees for this kind of averaging under mild assumptions on the autocorrelations of the underlying random dynamical system. We further discuss the implications of our results for a recently introduced adaptive step size control for Stochastic Gradient Descent (SGD), which uses $p$-EMA for averaging noisy observations.
Adaptive Step Sizes for Preconditioned Stochastic Gradient Descent
Nov 28, 2023This paper proposes a novel approach to adaptive step sizes in stochastic gradient descent (SGD) by utilizing quantities that we have identified as numerically traceable -- the Lipschitz constant for gradients and a concept of the local variance in search directions. Our findings yield a nearly hyperparameter-free algorithm for stochastic optimization, which has provable convergence properties when applied to quadratic problems and exhibits truly problem adaptive behavior on classical image classification tasks. Our framework enables the potential inclusion of a preconditioner, thereby enabling the implementation of adaptive step sizes for stochastic second-order optimization methods.
Sensitivity-Based Layer Insertion for Residual and Feedforward Neural Networks
Nov 27, 2023The training of neural networks requires tedious and often manual tuning of the network architecture. We propose a systematic method to insert new layers during the training process, which eliminates the need to choose a fixed network size before training. Our technique borrows techniques from constrained optimization and is based on first-order sensitivity information of the objective with respect to the virtual parameters that additional layers, if inserted, would offer. We consider fully connected feedforward networks with selected activation functions as well as residual neural networks. In numerical experiments, the proposed sensitivity-based layer insertion technique exhibits improved training decay, compared to not inserting the layer. Furthermore, the computational effort is reduced in comparison to inserting the layer from the beginning. The code is available at \url{https://github.com/LeonieKreis/layer_insertion_sensitivity_based}.
Frobenius-Type Norms and Inner Products of Matrices and Linear Maps with Applications to Neural Network Training
Nov 26, 2023The Frobenius norm is a frequent choice of norm for matrices. In particular, the underlying Frobenius inner product is typically used to evaluate the gradient of an objective with respect to matrix variable, such as those occuring in the training of neural networks. We provide a broader view on the Frobenius norm and inner product for linear maps or matrices, and establish their dependence on inner products in the domain and co-domain spaces. This shows that the classical Frobenius norm is merely one special element of a family of more general Frobenius-type norms. The significant extra freedom furnished by this realization can be used, among other things, to precondition neural network training.