 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRocqStar: Leveraging Similarity-driven Retrieval and Agentic Systems for Rocq generation
May 28, 2025Interactive Theorem Proving was repeatedly shown to be fruitful combined with Generative Artificial Intelligence. This paper assesses multiple approaches to Rocq generation and illuminates potential avenues for improvement. We highlight the importance of thorough premise selection for generating Rocq proofs and propose a novel approach, leveraging retrieval via a self-attentive embedder model. The evaluation of the designed approach shows up to 28% relative increase of the generator's performance. We tackle the problem of writing Rocq proofs using a multi-stage agentic system, tailored for formal verification, and demonstrate its high effectiveness. We conduct an ablation study and show the use of multi-agent debate on the planning stage of proof synthesis.
Can LLMs Enable Verification in Mainstream Programming?
Mar 18, 2025Although formal methods are capable of producing reliable software, they have seen minimal adoption in everyday programming. Automatic code generation using large language models is becoming increasingly widespread, but it rarely considers producing strong correctness guarantees. In this study, we explore the ability of LLMs to produce verified code in three verification languages (Dafny, Nagini, and Verus). To do so, we use manually curated datasets derived from the state-ofthe-art Python benchmark, HumanEval. We also assess what types of information are sufficient to achieve good-quality results.
CoqPilot, a plugin for LLM-based generation of proofs
Oct 25, 2024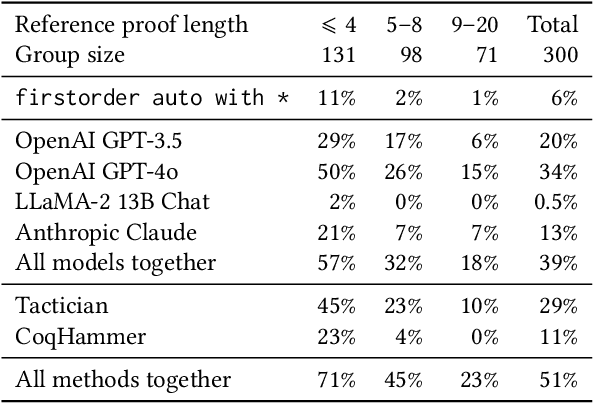
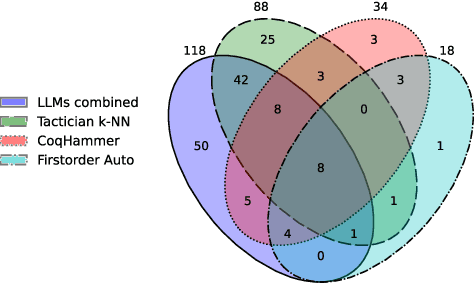
We present CoqPilot, a VS Code extension designed to help automate writing of Coq proofs. The plugin collects the parts of proofs marked with the admit tactic in a Coq file, i.e., proof holes, and combines LLMs along with non-machine-learning methods to generate proof candidates for the holes. Then, CoqPilot checks if each proof candidate solves the given subgoal and, if successful, replaces the hole with it. The focus of CoqPilot is twofold. Firstly, we want to allow users to seamlessly combine multiple Coq generation approaches and provide a zero-setup experience for our tool. Secondly, we want to deliver a platform for LLM-based experiments on Coq proof generation. We developed a benchmarking system for Coq generation methods, available in the plugin, and conducted an experiment using it, showcasing the framework's possibilities. Demo of CoqPilot is available at: https://youtu.be/oB1Lx-So9Lo. Code at: https://github.com/JetBrains-Research/coqpilot