 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitLight: An Exploratory Toolkit for Recommender Systems Datasets and Splits
Feb 22, 2026Offline evaluation of recommender systems is often affected by hidden, under-documented choices in data preparation. Seemingly minor decisions in filtering, handling repeats, cold-start treatment, and splitting strategy design can substantially reorder model rankings and undermine reproducibility and cross-paper comparability. In this paper, we introduce SplitLight, an open-source exploratory toolkit that enables researchers and practitioners designing preprocessing and splitting pipelines or reviewing external artifacts to make these decisions measurable, comparable, and reportable. Given an interaction log and derived split subsets, SplitLight analyzes core and temporal dataset statistics, characterizes repeat consumption patterns and timestamp anomalies, and diagnoses split validity, including temporal leakage, cold-user/item exposure, and distribution shifts. SplitLight further allows side-by-side comparison of alternative splitting strategies through comprehensive aggregated summaries and interactive visualizations. Delivered as both a Python toolkit and an interactive no-code interface, SplitLight produces audit summaries that justify evaluation protocols and support transparent, reliable, and comparable experimentation in recommender systems research and industry.
Topological Metric for Unsupervised Embedding Quality Evaluation
Dec 17, 2025Modern representation learning increasingly relies on unsupervised and self-supervised methods trained on large-scale unlabeled data. While these approaches achieve impressive generalization across tasks and domains, evaluating embedding quality without labels remains an open challenge. In this work, we propose Persistence, a topology-aware metric based on persistent homology that quantifies the geometric structure and topological richness of embedding spaces in a fully unsupervised manner. Unlike metrics that assume linear separability or rely on covariance structure, Persistence captures global and multi-scale organization. Empirical results across diverse domains show that Persistence consistently achieves top-tier correlations with downstream performance, outperforming existing unsupervised metrics and enabling reliable model and hyperparameter selection.
Encode Me If You Can: Learning Universal User Representations via Event Sequence Autoencoding
Aug 11, 2025Building universal user representations that capture the essential aspects of user behavior is a crucial task for modern machine learning systems. In real-world applications, a user's historical interactions often serve as the foundation for solving a wide range of predictive tasks, such as churn prediction, recommendations, or lifetime value estimation. Using a task-independent user representation that is effective across all such tasks can reduce the need for task-specific feature engineering and model retraining, leading to more scalable and efficient machine learning pipelines. The goal of the RecSys Challenge 2025 by Synerise was to develop such Universal Behavioral Profiles from logs of past user behavior, which included various types of events such as product purchases, page views, and search queries. We propose a method that transforms the entire user interaction history into a single chronological sequence and trains a GRU-based autoencoder to reconstruct this sequence from a fixed-size vector. If the model can accurately reconstruct the sequence, the latent vector is expected to capture the key behavioral patterns. In addition to this core model, we explored several alternative methods for generating user embeddings and combined them by concatenating their output vectors into a unified representation. This ensemble strategy further improved generalization across diverse downstream tasks and helped our team, ai_lab_recsys, achieve second place in the RecSys Challenge 2025.
Sparse Autoencoders for Sequential Recommendation Models: Interpretation and Flexible Control
Jul 16, 2025Many current state-of-the-art models for sequential recommendations are based on transformer architectures. Interpretation and explanation of such black box models is an important research question, as a better understanding of their internals can help understand, influence, and control their behavior, which is very important in a variety of real-world applications. Recently sparse autoencoders (SAE) have been shown to be a promising unsupervised approach for extracting interpretable features from language models. These autoencoders learn to reconstruct hidden states of the transformer's internal layers from sparse linear combinations of directions in their activation space. This paper is focused on the application of SAE to the sequential recommendation domain. We show that this approach can be successfully applied to the transformer trained on a sequential recommendation task: learned directions turn out to be more interpretable and monosemantic than the original hidden state dimensions. Moreover, we demonstrate that the features learned by SAE can be used to effectively and flexibly control the model's behavior, providing end-users with a straightforward method to adjust their recommendations to different custom scenarios and contexts.
Autoregressive Generation Strategies for Top-K Sequential Recommendations
Sep 26, 2024The goal of modern sequential recommender systems is often formulated in terms of next-item prediction. In this paper, we explore the applicability of generative transformer-based models for the Top-K sequential recommendation task, where the goal is to predict items a user is likely to interact with in the "near future". We explore commonly used autoregressive generation strategies, including greedy decoding, beam search, and temperature sampling, to evaluate their performance for the Top-K sequential recommendation task. In addition, we propose novel Reciprocal Rank Aggregation (RRA) and Relevance Aggregation (RA) generation strategies based on multi-sequence generation with temperature sampling and subsequent aggregation. Experiments on diverse datasets give valuable insights regarding commonly used strategies' applicability and show that suggested approaches improve performance on longer time horizons compared to widely-used Top-K prediction approach and single-sequence autoregressive generation strategies.
RePlay: a Recommendation Framework for Experimentation and Production Use
Sep 11, 2024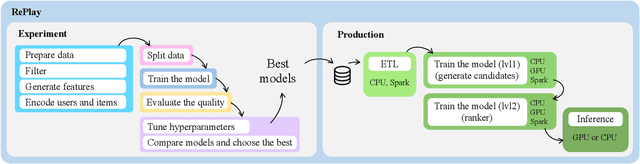
Using a single tool to build and compare recommender systems significantly reduces the time to market for new models. In addition, the comparison results when using such tools look more consistent. This is why many different tools and libraries for researchers in the field of recommendations have recently appeared. Unfortunately, most of these frameworks are aimed primarily at researchers and require modification for use in production due to the inability to work on large datasets or an inappropriate architecture. In this demo, we present our open-source toolkit RePlay - a framework containing an end-to-end pipeline for building recommender systems, which is ready for production use. RePlay also allows you to use a suitable stack for the pipeline on each stage: Pandas, Polars, or Spark. This allows the library to scale computations and deploy to a cluster. Thus, RePlay allows data scientists to easily move from research mode to production mode using the same interfaces.
Does It Look Sequential? An Analysis of Datasets for Evaluation of Sequential Recommendations
Aug 21, 2024Sequential recommender systems are an important and demanded area of research. Such systems aim to use the order of interactions in a user's history to predict future interactions. The premise is that the order of interactions and sequential patterns play an essential role. Therefore, it is crucial to use datasets that exhibit a sequential structure to evaluate sequential recommenders properly. We apply several methods based on the random shuffling of the user's sequence of interactions to assess the strength of sequential structure across 15 datasets, frequently used for sequential recommender systems evaluation in recent research papers presented at top-tier conferences. As shuffling explicitly breaks sequential dependencies inherent in datasets, we estimate the strength of sequential patterns by comparing metrics for shuffled and original versions of the dataset. Our findings show that several popular datasets have a rather weak sequential structure.
Turning Dross Into Gold Loss: is BERT4Rec really better than SASRec?
Sep 14, 2023Recently sequential recommendations and next-item prediction task has become increasingly popular in the field of recommender systems. Currently, two state-of-the-art baselines are Transformer-based models SASRec and BERT4Rec. Over the past few years, there have been quite a few publications comparing these two algorithms and proposing new state-of-the-art models. In most of the publications, BERT4Rec achieves better performance than SASRec. But BERT4Rec uses cross-entropy over softmax for all items, while SASRec uses negative sampling and calculates binary cross-entropy loss for one positive and one negative item. In our work, we show that if both models are trained with the same loss, which is used by BERT4Rec, then SASRec will significantly outperform BERT4Rec both in terms of quality and training speed. In addition, we show that SASRec could be effectively trained with negative sampling and still outperform BERT4Rec, but the number of negative examples should be much larger than one.