 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Centric Approach to Constrained Machine Learning: A Case Study on Conway's Game of Life
Aug 23, 2024This paper focuses on a data-centric approach to machine learning applications in the context of Conway's Game of Life. Specifically, we consider the task of training a minimal architecture network to learn the transition rules of Game of Life for a given number of steps ahead, which is known to be challenging due to restrictions on the allowed number of trainable parameters. An extensive quantitative analysis showcases the benefits of utilizing a strategically designed training dataset, with its advantages persisting regardless of other parameters of the learning configuration, such as network initialization weights or optimization algorithm. Importantly, our findings highlight the integral role of domain expert insights in creating effective machine learning applications for constrained real-world scenarios.
Zero-Shot Recommendations with Pre-Trained Large Language Models for Multimodal Nudging
Sep 02, 2023



We present a method for zero-shot recommendation of multimodal non-stationary content that leverages recent advancements in the field of generative AI. We propose rendering inputs of different modalities as textual descriptions and to utilize pre-trained LLMs to obtain their numerical representations by computing semantic embeddings. Once unified representations of all content items are obtained, the recommendation can be performed by computing an appropriate similarity metric between them without any additional learning. We demonstrate our approach on a synthetic multimodal nudging environment, where the inputs consist of tabular, textual, and visual data.
Simulated Contextual Bandits for Personalization Tasks from Recommendation Datasets
Oct 12, 2022


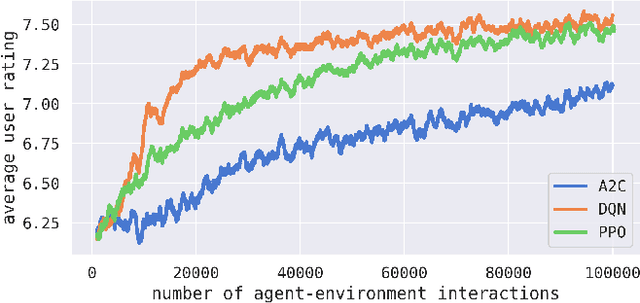
We propose a method for generating simulated contextual bandit environments for personalization tasks from recommendation datasets like MovieLens, Netflix, Last.fm, Million Song, etc. This allows for personalization environments to be developed based on real-life data to reflect the nuanced nature of real-world user interactions. The obtained environments can be used to develop methods for solving personalization tasks, algorithm benchmarking, model simulation, and more. We demonstrate our approach with numerical examples on MovieLens and IMDb datasets.