 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Pipeline Tools for Data Engineering
Jun 12, 2024
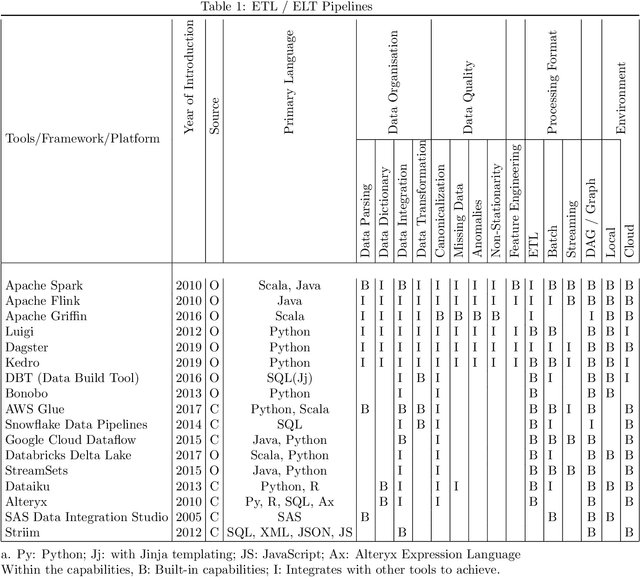
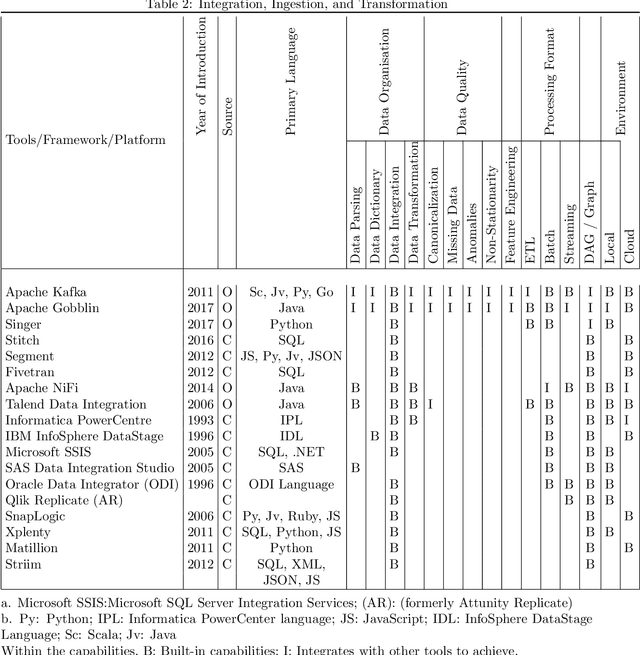
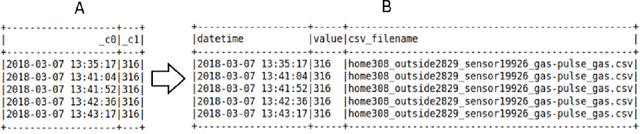
Currently, a variety of pipeline tools are available for use in data engineering. Data scientists can use these tools to resolve data wrangling issues associated with data and accomplish some data engineering tasks from data ingestion through data preparation to utilization as input for machine learning (ML). Some of these tools have essential built-in components or can be combined with other tools to perform desired data engineering operations. While some tools are wholly or partly commercial, several open-source tools are available to perform expert-level data engineering tasks. This survey examines the broad categories and examples of pipeline tools based on their design and data engineering intentions. These categories are Extract Transform Load/Extract Load Transform (ETL/ELT), pipelines for Data Integration, Ingestion, and Transformation, Data Pipeline Orchestration and Workflow Management, and Machine Learning Pipelines. The survey also provides a broad outline of the utilization with examples within these broad groups and finally, a discussion is presented with case studies indicating the usage of pipeline tools for data engineering. The studies present some first-user application experiences with sample data, some complexities of the applied pipeline, and a summary note of approaches to using these tools to prepare data for machine learning.