 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacking-Based Deep Neural Network: Deep Analytic Network for Pattern Classification
Nov 17, 2018

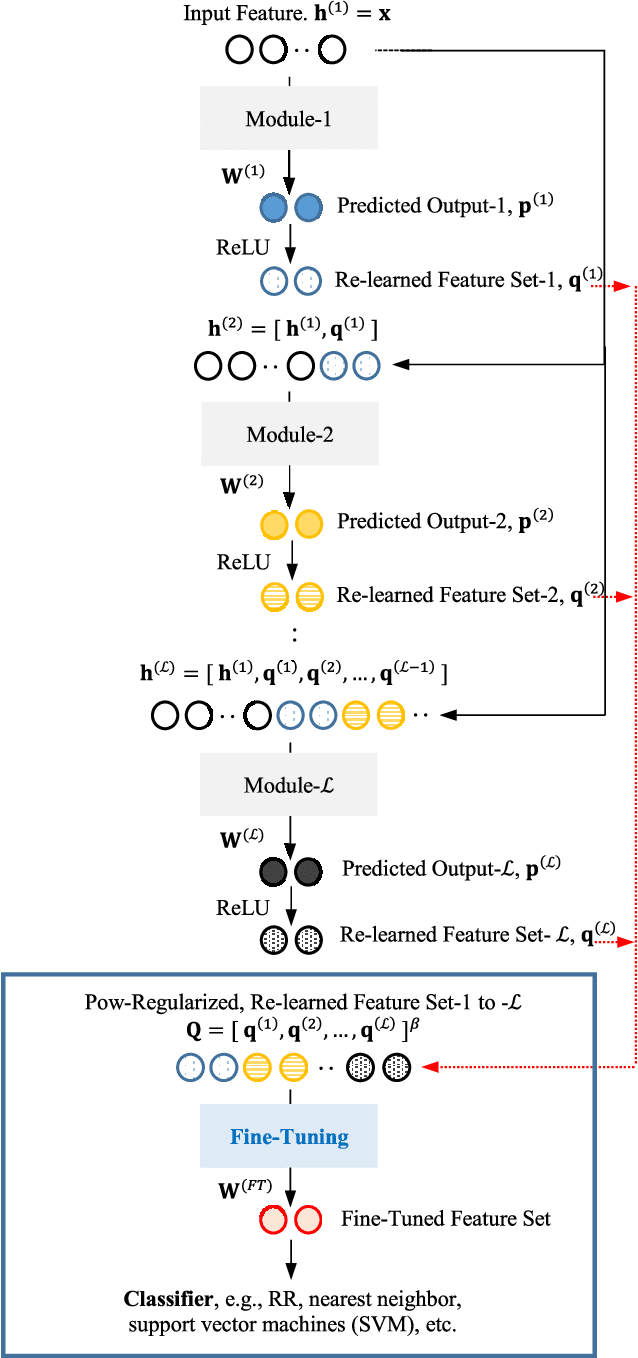

Stacking-based deep neural network (S-DNN) is aggregated with pluralities of basic learning modules, one after another, to synthesize a deep neural network (DNN) alternative for pattern classification. Contrary to the DNNs trained end to end by backpropagation (BP), each S-DNN layer, i.e., a self-learnable module, is to be trained decisively and independently without BP intervention. In this paper, a ridge regression-based S-DNN, dubbed deep analytic network (DAN), along with its kernelization (K-DAN), are devised for multilayer feature re-learning from the pre-extracted baseline features and the structured features. Our theoretical formulation demonstrates that DAN/K-DAN re-learn by perturbing the intra/inter-class variations, apart from diminishing the prediction errors. We scrutinize the DAN/K-DAN performance for pattern classification on datasets of varying domains - faces, handwritten digits, generic objects, to name a few. Unlike the typical BP-optimized DNNs to be trained from gigantic datasets by GPU, we disclose that DAN/K-DAN are trainable using only CPU even for small-scale training sets. Our experimental results disclose that DAN/K-DAN outperform the present S-DNNs and also the BP-trained DNNs, including multiplayer perceptron, deep belief network, etc., without data augmentation applied.
Stacking-based Deep Neural Network: Deep Analytic Network on Convolutional Spectral Histogram Features
May 21, 2017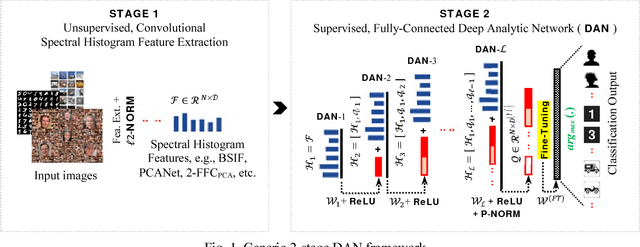
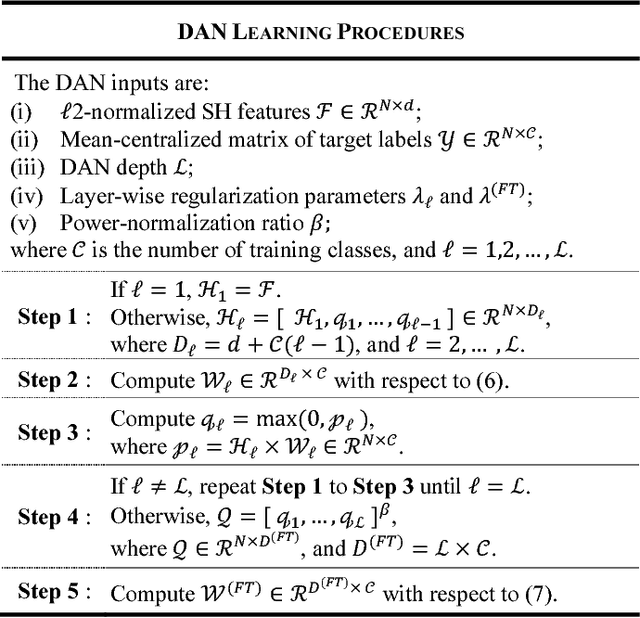

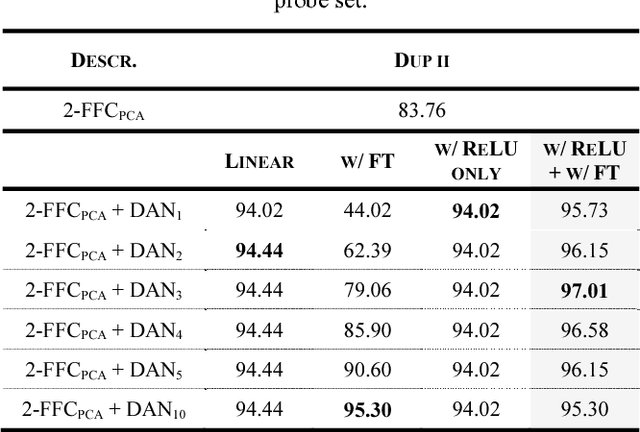
Stacking-based deep neural network (S-DNN), in general, denotes a deep neural network (DNN) resemblance in terms of its very deep, feedforward network architecture. The typical S-DNN aggregates a variable number of individually learnable modules in series to assemble a DNN-alike alternative to the targeted object recognition tasks. This work likewise devises an S-DNN instantiation, dubbed deep analytic network (DAN), on top of the spectral histogram (SH) features. The DAN learning principle relies on ridge regression, and some key DNN constituents, specifically, rectified linear unit, fine-tuning, and normalization. The DAN aptitude is scrutinized on three repositories of varying domains, including FERET (faces), MNIST (handwritten digits), and CIFAR10 (natural objects). The empirical results unveil that DAN escalates the SH baseline performance over a sufficiently deep layer.