 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"You still have to study" -- On the Security of LLM generated code
Aug 13, 2024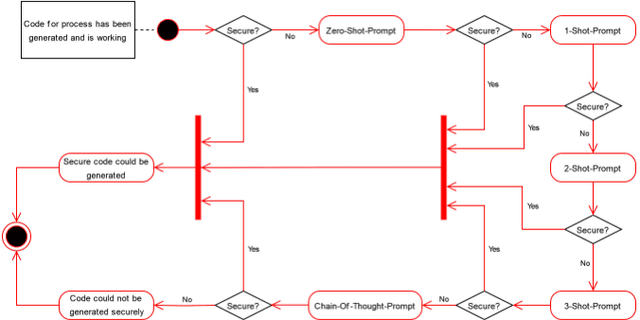



We witness an increasing usage of AI-assistants even for routine (classroom) programming tasks. However, the code generated on basis of a so called "prompt" by the programmer does not always meet accepted security standards. On the one hand, this may be due to lack of best-practice examples in the training data. On the other hand, the actual quality of the programmers prompt appears to influence whether generated code contains weaknesses or not. In this paper we analyse 4 major LLMs with respect to the security of generated code. We do this on basis of a case study for the Python and Javascript language, using the MITRE CWE catalogue as the guiding security definition. Our results show that using different prompting techniques, some LLMs initially generate 65% code which is deemed insecure by a trained security engineer. On the other hand almost all analysed LLMs will eventually generate code being close to 100% secure with increasing manual guidance of a skilled engineer.
Deep-Learning-based Vulnerability Detection in Binary Executables
Nov 25, 2022The identification of vulnerabilities is an important element in the software development life cycle to ensure the security of software. While vulnerability identification based on the source code is a well studied field, the identification of vulnerabilities on basis of a binary executable without the corresponding source code is more challenging. Recent research [1] has shown, how such detection can be achieved by deep learning methods. However, that particular approach is limited to the identification of only 4 types of vulnerabilities. Subsequently, we analyze to what extent we could cover the identification of a larger variety of vulnerabilities. Therefore, a supervised deep learning approach using recurrent neural networks for the application of vulnerability detection based on binary executables is used. The underlying basis is a dataset with 50,651 samples of vulnerable code in the form of a standardized LLVM Intermediate Representation. The vectorised features of a Word2Vec model are used to train different variations of three basic architectures of recurrent neural networks (GRU, LSTM, SRNN). A binary classification was established for detecting the presence of an arbitrary vulnerability, and a multi-class model was trained for the identification of the exact vulnerability, which achieved an out-of-sample accuracy of 88% and 77%, respectively. Differences in the detection of different vulnerabilities were also observed, with non-vulnerable samples being detected with a particularly high precision of over 98%. Thus, the methodology presented allows an accurate detection of 23 (compared to 4 [1]) vulnerabilities.
Creation and Detection of German Voice Deepfakes
Aug 02, 2021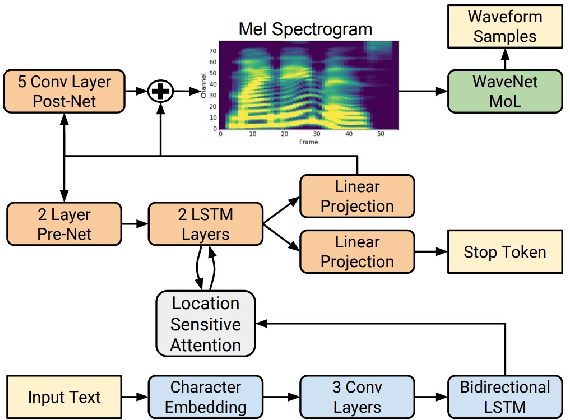
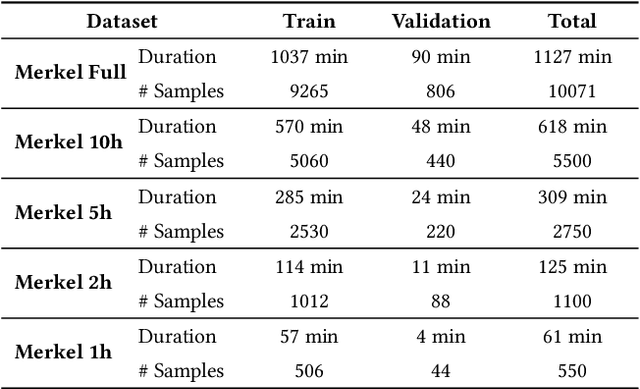
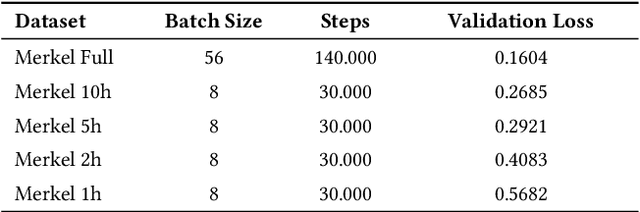
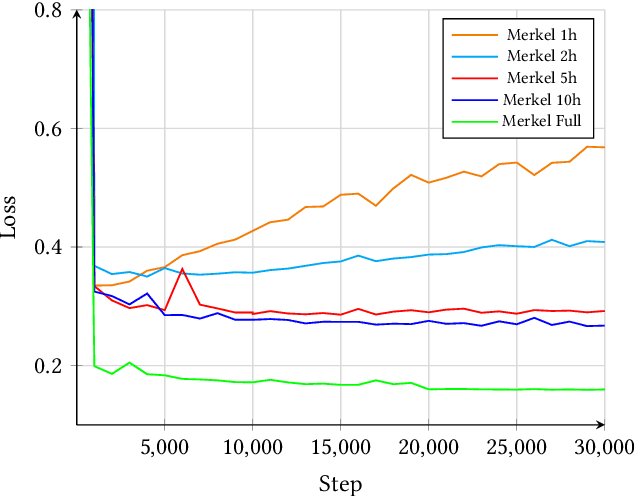
Synthesizing voice with the help of machine learning techniques has made rapid progress over the last years [1] and first high profile fraud cases have been recently reported [2]. Given the current increase in using conferencing tools for online teaching, we question just how easy (i.e. needed data, hardware, skill set) it would be to create a convincing voice fake. We analyse how much training data a participant (e.g. a student) would actually need to fake another participants voice (e.g. a professor). We provide an analysis of the existing state of the art in creating voice deep fakes, as well as offer detailed technical guidance and evidence of just how much effort is needed to copy a voice. A user study with more than 100 participants shows how difficult it is to identify real and fake voice (on avg. only 37 percent can distinguish between real and fake voice of a professor). With a focus on German language and an online teaching environment we discuss the societal implications as well as demonstrate how to use machine learning techniques to possibly detect such fakes.