Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Similarity: Computationally Reproducing the Scholar's Interests
Dec 14, 2018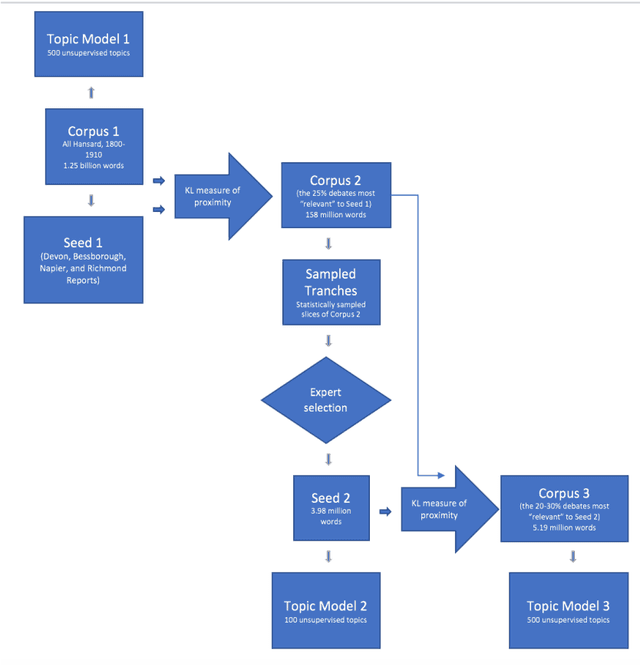
Computerized document classification already orders the news articles that Apple's "News" app or Google's "personalized search" feature groups together to match a reader's interests. The invisible and therefore illegible decisions that go into these tailored searches have been the subject of a critique by scholars who emphasize that our intelligence about documents is only as good as our ability to understand the criteria of search. This article will attempt to unpack the procedures used in computational classification of texts, translating them into term legible to humanists, and examining opportunities to render the computational text classification process subject to expert critique and improvement.
* to be submitted
Via