 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHackSynth: LLM Agent and Evaluation Framework for Autonomous Penetration Testing
Dec 02, 2024We introduce HackSynth, a novel Large Language Model (LLM)-based agent capable of autonomous penetration testing. HackSynth's dual-module architecture includes a Planner and a Summarizer, which enable it to generate commands and process feedback iteratively. To benchmark HackSynth, we propose two new Capture The Flag (CTF)-based benchmark sets utilizing the popular platforms PicoCTF and OverTheWire. These benchmarks include two hundred challenges across diverse domains and difficulties, providing a standardized framework for evaluating LLM-based penetration testing agents. Based on these benchmarks, extensive experiments are presented, analyzing the core parameters of HackSynth, including creativity (temperature and top-p) and token utilization. Multiple open source and proprietary LLMs were used to measure the agent's capabilities. The experiments show that the agent performed best with the GPT-4o model, better than what the GPT-4o's system card suggests. We also discuss the safety and predictability of HackSynth's actions. Our findings indicate the potential of LLM-based agents in advancing autonomous penetration testing and the importance of robust safeguards. HackSynth and the benchmarks are publicly available to foster research on autonomous cybersecurity solutions.
Enhancing pretraining efficiency for medical image segmentation via transferability metrics
Oct 24, 2024



In medical image segmentation tasks, the scarcity of labeled training data poses a significant challenge when training deep neural networks. When using U-Net-style architectures, it is common practice to address this problem by pretraining the encoder part on a large general-purpose dataset like ImageNet. However, these methods are resource-intensive and do not guarantee improved performance on the downstream task. In this paper we investigate a variety of training setups on medical image segmentation datasets, using ImageNet-pretrained models. By examining over 300 combinations of models, datasets, and training methods, we find that shorter pretraining often leads to better results on the downstream task, providing additional proof to the well-known fact that the accuracy of the model on ImageNet is a poor indicator for downstream performance. As our main contribution, we introduce a novel transferability metric, based on contrastive learning, that measures how robustly a pretrained model is able to represent the target data. In contrast to other transferability scores, our method is applicable to the case of transferring from ImageNet classification to medical image segmentation. We apply our robustness score by measuring it throughout the pretraining phase to indicate when the model weights are optimal for downstream transfer. This reduces pretraining time and improves results on the target task.
Parameter Estimation of Long Memory Stochastic Processes with Deep Neural Networks
Oct 03, 2024



We present a purely deep neural network-based approach for estimating long memory parameters of time series models that incorporate the phenomenon of long-range dependence. Parameters, such as the Hurst exponent, are critical in characterizing the long-range dependence, roughness, and self-similarity of stochastic processes. The accurate and fast estimation of these parameters holds significant importance across various scientific disciplines, including finance, physics, and engineering. We harnessed efficient process generators to provide high-quality synthetic training data, enabling the training of scale-invariant 1D Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) models. Our neural models outperform conventional statistical methods, even those augmented with neural networks. The precision, speed, consistency, and robustness of our estimators are demonstrated through experiments involving fractional Brownian motion (fBm), the Autoregressive Fractionally Integrated Moving Average (ARFIMA) process, and the fractional Ornstein-Uhlenbeck (fOU) process. We believe that our work will inspire further research in the field of stochastic process modeling and parameter estimation using deep learning techniques.
LlamBERT: Large-scale low-cost data annotation in NLP
Mar 23, 2024Large Language Models (LLMs), such as GPT-4 and Llama 2, show remarkable proficiency in a wide range of natural language processing (NLP) tasks. Despite their effectiveness, the high costs associated with their use pose a challenge. We present LlamBERT, a hybrid approach that leverages LLMs to annotate a small subset of large, unlabeled databases and uses the results for fine-tuning transformer encoders like BERT and RoBERTa. This strategy is evaluated on two diverse datasets: the IMDb review dataset and the UMLS Meta-Thesaurus. Our results indicate that the LlamBERT approach slightly compromises on accuracy while offering much greater cost-effectiveness.
Deep learning the Hurst parameter of linear fractional processes and assessing its reliability
Jan 03, 2024This research explores the reliability of deep learning, specifically Long Short-Term Memory (LSTM) networks, for estimating the Hurst parameter in fractional stochastic processes. The study focuses on three types of processes: fractional Brownian motion (fBm), fractional Ornstein-Uhlenbeck (fOU) process, and linear fractional stable motions (lfsm). The work involves a fast generation of extensive datasets for fBm and fOU to train the LSTM network on a large volume of data in a feasible time. The study analyses the accuracy of the LSTM network's Hurst parameter estimation regarding various performance measures like RMSE, MAE, MRE, and quantiles of the absolute and relative errors. It finds that LSTM outperforms the traditional statistical methods in the case of fBm and fOU processes; however, it has limited accuracy on lfsm processes. The research also delves into the implications of training length and valuation sequence length on the LSTM's performance. The methodology is applied by estimating the Hurst parameter in Li-ion battery degradation data and obtaining confidence bounds for the estimation. The study concludes that while deep learning methods show promise in parameter estimation of fractional processes, their effectiveness is contingent on the process type and the quality of training data.
Dilated Convolutional Neural Networks for Lightweight Diacritics Restoration
Jan 18, 2022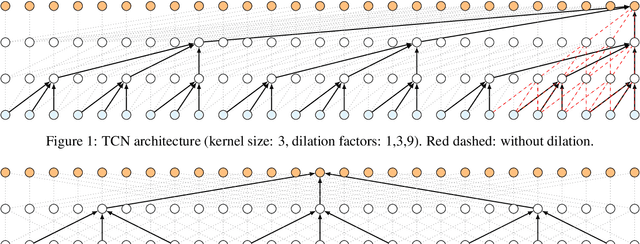
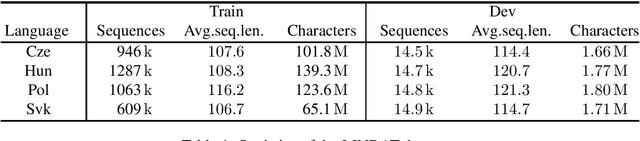

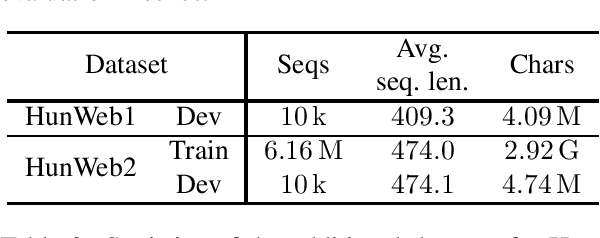
Diacritics restoration has become a ubiquitous task in the Latin-alphabet-based English-dominated Internet language environment. In this paper, we describe a small footprint 1D dilated convolution-based approach which operates on a character-level. We find that solutions based on 1D dilated convolutional neural networks are competitive alternatives to models based on recursive neural networks or linguistic modeling for the task of diacritics restoration. Our solution surpasses the performance of similarly sized models and is also competitive with larger models. A special feature of our solution is that it even runs locally in a web browser. We also provide a working example of this browser-based implementation. Our model is evaluated on different corpora, with emphasis on the Hungarian language. We performed comparative measurements about the generalization power of the model in relation to three Hungarian corpora. We also analyzed the errors to understand the limitation of corpus-based self-supervised training.
Attention U-Net Based Adversarial Architectures for Chest X-ray Lung Segmentation
Mar 23, 2020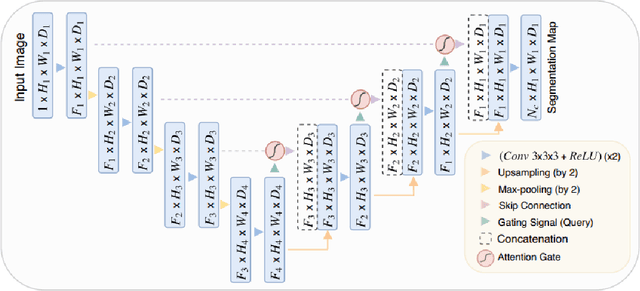
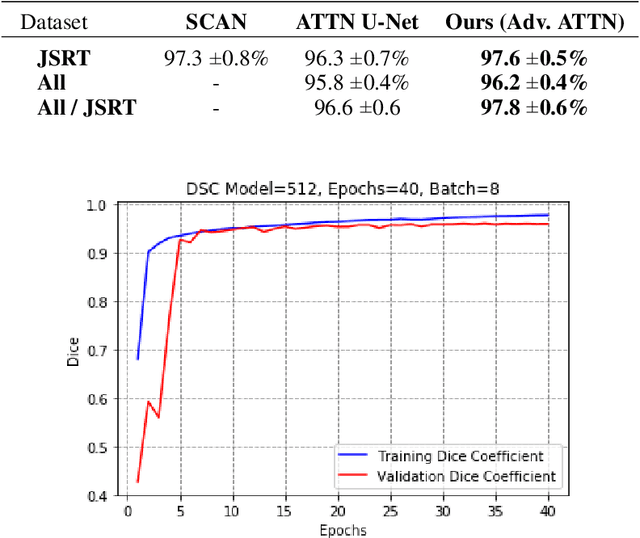
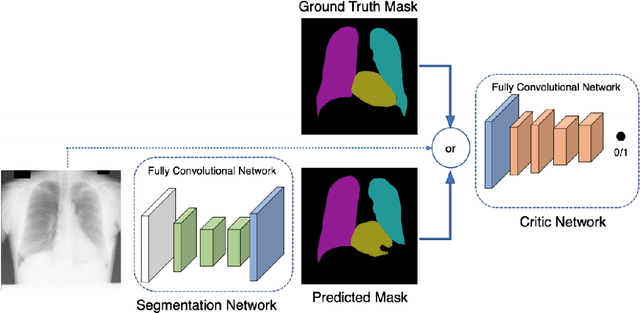
Chest X-ray is the most common test among medical imaging modalities. It is applied for detection and differentiation of, among others, lung cancer, tuberculosis, and pneumonia, the last with importance due to the COVID-19 disease. Integrating computer-aided detection methods into the radiologist diagnostic pipeline, greatly reduces the doctors' workload, increasing reliability and quantitative analysis. Here we present a novel deep learning approach for lung segmentation, a basic, but arduous task in the diagnostic pipeline. Our method uses state-of-the-art fully convolutional neural networks in conjunction with an adversarial critic model. It generalized well to CXR images of unseen datasets with different patient profiles, achieving a final DSC of 97.5% on the JSRT dataset.