 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-Driven Prompt Optimization for Arithmetic Reasoning
Dec 15, 2025Recent advancements in artificial intelligence have sparked interest in industrial agents capable of supporting analysts in regulated sectors, such as finance and healthcare, within tabular data workflows. A key capability for such systems is performing accurate arithmetic operations on structured data while ensuring sensitive information never leaves secure, on-premises environments. Here, we introduce an error-driven optimization framework for arithmetic reasoning that enhances a Code Generation Agent (CGA), specifically applied to on-premises small language models (SLMs). Through a systematic evaluation of a leading SLM (Qwen3 4B), we find that while the base model exhibits fundamental limitations in arithmetic tasks, our proposed error-driven method, which clusters erroneous predictions to refine prompt-rules iteratively, dramatically improves performance, elevating the model's accuracy to 70.8\%. Our results suggest that developing reliable, interpretable, and industrially deployable AI assistants can be achieved not only through costly fine-tuning but also via systematic, error-driven prompt optimization, enabling small models to surpass larger language models (GPT-3.5 Turbo) in a privacy-compliant manner.
Efficient Learning of Model Weights via Changing Features During Training
Feb 21, 2020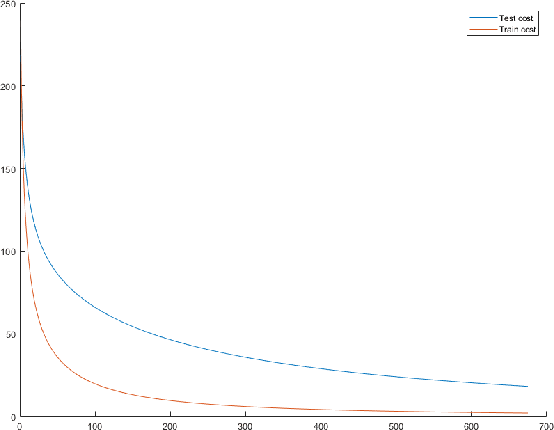
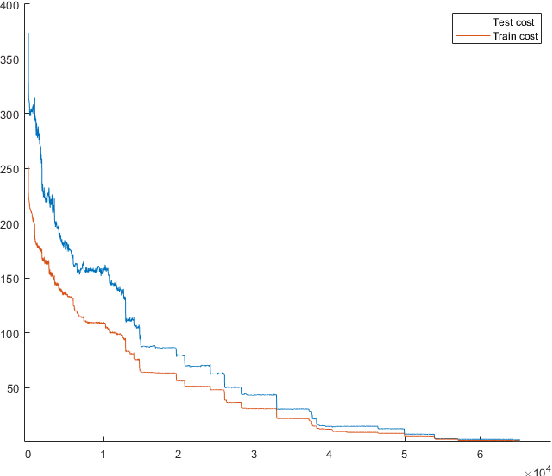
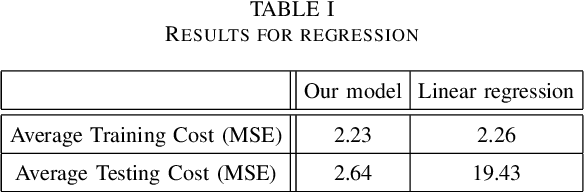

In this paper, we propose a machine learning model, which dynamically changes the features during training. Our main motivation is to update the model in a small content during the training process with replacing less descriptive features to new ones from a large pool. The main benefit is coming from the fact that opposite to the common practice we do not start training a new model from the scratch, but can keep the already learned weights. This procedure allows the scan of a large feature pool which together with keeping the complexity of the model leads to an increase of the model accuracy within the same training time. The efficiency of our approach is demonstrated in several classic machine learning scenarios including linear regression and neural network-based training. As a specific analysis towards signal processing, we have successfully tested our approach on the database MNIST for digit classification considering single pixel and pixel-pairs intensities as possible features.