 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMM-Conv: Scalar Matrix Multiplication with Zero Packing for Accelerated Convolution
Nov 23, 2024

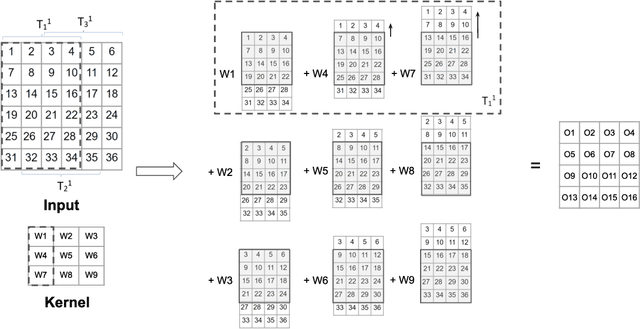

We present a novel approach for accelerating convolutions during inference for CPU-based architectures. The most common method of computation involves packing the image into the columns of a matrix (im2col) and performing general matrix multiplication (GEMM) with a matrix of weights. This results in two main drawbacks: (a) im2col requires a large memory buffer and can experience inefficient memory access, and (b) while GEMM is highly optimized for scientific matrices multiplications, it is not well suited for convolutions. We propose an approach that takes advantage of scalar-matrix multiplication and reduces memory overhead. Our experiments with commonly used network architectures demonstrate a significant speedup compared to existing indirect methods.