 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Analysis of EEGs Using Big Data and Hybrid Deep Learning Architectures
Dec 28, 2017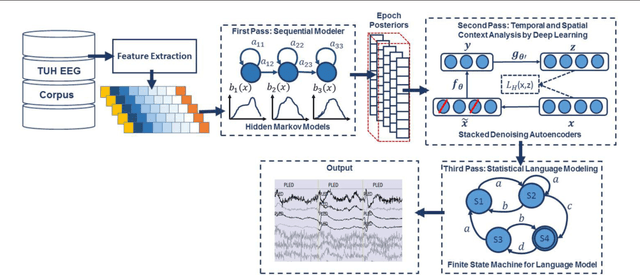
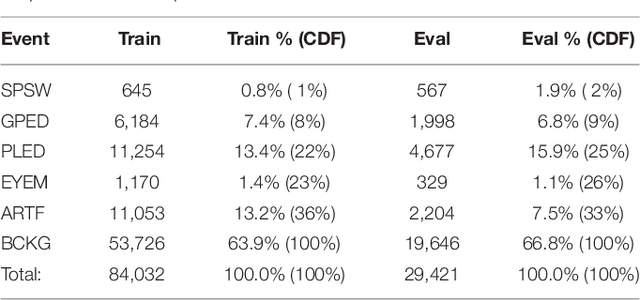
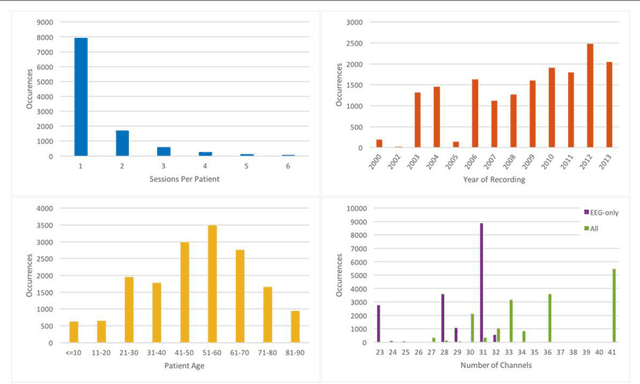

Objective: A clinical decision support tool that automatically interprets EEGs can reduce time to diagnosis and enhance real-time applications such as ICU monitoring. Clinicians have indicated that a sensitivity of 95% with a specificity below 5% was the minimum requirement for clinical acceptance. We propose a highperformance classification system based on principles of big data and machine learning. Methods: A hybrid machine learning system that uses hidden Markov models (HMM) for sequential decoding and deep learning networks for postprocessing is proposed. These algorithms were trained and evaluated using the TUH EEG Corpus, which is the world's largest publicly available database of clinical EEG data. Results: Our approach delivers a sensitivity above 90% while maintaining a specificity below 5%. This system detects three events of clinical interest: (1) spike and/or sharp waves, (2) periodic lateralized epileptiform discharges, (3) generalized periodic epileptiform discharges. It also detects three events used to model background noise: (1) artifacts, (2) eye movement (3) background. Conclusions: A hybrid HMM/deep learning system can deliver a low false alarm rate on EEG event detection, making automated analysis a viable option for clinicians. Significance: The TUH EEG Corpus enables application of highly data consumptive machine learning algorithms to EEG analysis. Performance is approaching clinical acceptance for real-time applications.
A Nonparametric Bayesian Approach for Spoken Term detection by Example Query
Jun 20, 2016

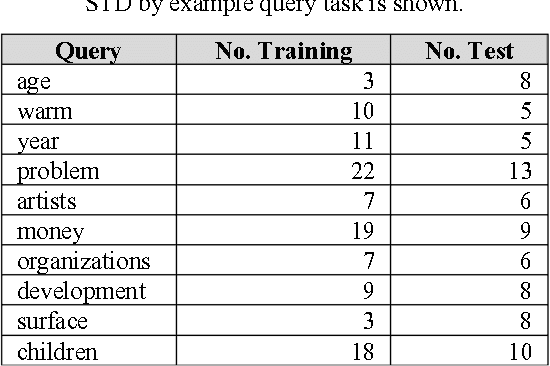
State of the art speech recognition systems use data-intensive context-dependent phonemes as acoustic units. However, these approaches do not translate well to low resourced languages where large amounts of training data is not available. For such languages, automatic discovery of acoustic units is critical. In this paper, we demonstrate the application of nonparametric Bayesian models to acoustic unit discovery. We show that the discovered units are correlated with phonemes and therefore are linguistically meaningful. We also present a spoken term detection (STD) by example query algorithm based on these automatically learned units. We show that our proposed system produces a P@N of 61.2% and an EER of 13.95% on the TIMIT dataset. The improvement in the EER is 5% while P@N is only slightly lower than the best reported system in the literature.