 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Advanced Features Extraction Module for Remote Sensing Image Super-Resolution
May 07, 2024In recent years, convolutional neural networks (CNNs) have achieved remarkable advancement in the field of remote sensing image super-resolution due to the complexity and variability of textures and structures in remote sensing images (RSIs), which often repeat in the same images but differ across others. Current deep learning-based super-resolution models focus less on high-frequency features, which leads to suboptimal performance in capturing contours, textures, and spatial information. State-of-the-art CNN-based methods now focus on the feature extraction of RSIs using attention mechanisms. However, these methods are still incapable of effectively identifying and utilizing key content attention signals in RSIs. To solve this problem, we proposed an advanced feature extraction module called Channel and Spatial Attention Feature Extraction (CSA-FE) for effectively extracting the features by using the channel and spatial attention incorporated with the standard vision transformer (ViT). The proposed method trained over the UCMerced dataset on scales 2, 3, and 4. The experimental results show that our proposed method helps the model focus on the specific channels and spatial locations containing high-frequency information so that the model can focus on relevant features and suppress irrelevant ones, which enhances the quality of super-resolved images. Our model achieved superior performance compared to various existing models.
* Preprint of paper from The 21st International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology or ECTI-CON 2024, Khon Kaen, Thailand
LongFin: A Multimodal Document Understanding Model for Long Financial Domain Documents
Jan 26, 2024Document AI is a growing research field that focuses on the comprehension and extraction of information from scanned and digital documents to make everyday business operations more efficient. Numerous downstream tasks and datasets have been introduced to facilitate the training of AI models capable of parsing and extracting information from various document types such as receipts and scanned forms. Despite these advancements, both existing datasets and models fail to address critical challenges that arise in industrial contexts. Existing datasets primarily comprise short documents consisting of a single page, while existing models are constrained by a limited maximum length, often set at 512 tokens. Consequently, the practical application of these methods in financial services, where documents can span multiple pages, is severely impeded. To overcome these challenges, we introduce LongFin, a multimodal document AI model capable of encoding up to 4K tokens. We also propose the LongForms dataset, a comprehensive financial dataset that encapsulates several industrial challenges in financial documents. Through an extensive evaluation, we demonstrate the effectiveness of the LongFin model on the LongForms dataset, surpassing the performance of existing public models while maintaining comparable results on existing single-page benchmarks.
Machine Learning Etudes in Astrophysics: Selection Functions for Mock Cluster Catalogs
Jan 21, 2015
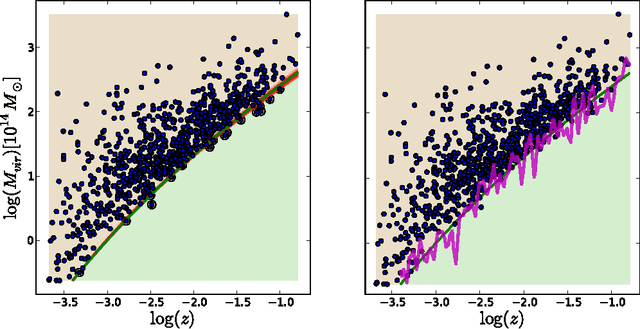
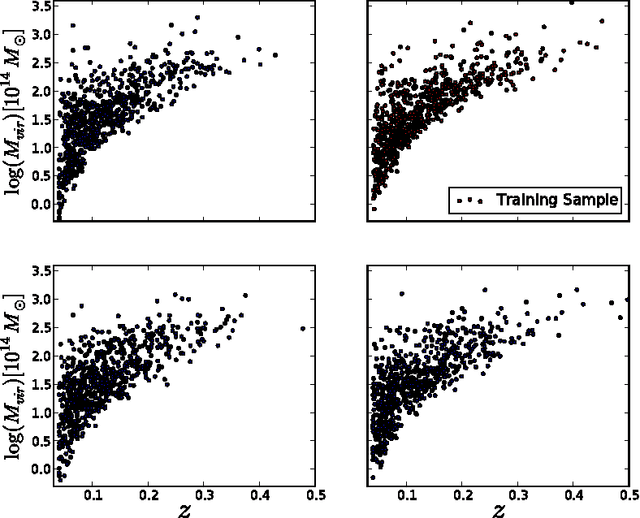

Making mock simulated catalogs is an important component of astrophysical data analysis. Selection criteria for observed astronomical objects are often too complicated to be derived from first principles. However the existence of an observed group of objects is a well-suited problem for machine learning classification. In this paper we use one-class classifiers to learn the properties of an observed catalog of clusters of galaxies from ROSAT and to pick clusters from mock simulations that resemble the observed ROSAT catalog. We show how this method can be used to study the cross-correlations of thermal Sunya'ev-Zeldovich signals with number density maps of X-ray selected cluster catalogs. The method reduces the bias due to hand-tuning the selection function and is readily scalable to large catalogs with a high-dimensional space of astrophysical features.