 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Noise in the Sample Complexity of Learning Recurrent Neural Networks: Exponential Gaps for Long Sequences
May 28, 2023
We consider the class of noisy multi-layered sigmoid recurrent neural networks with $w$ (unbounded) weights for classification of sequences of length $T$, where independent noise distributed according to $\mathcal{N}(0,\sigma^2)$ is added to the output of each neuron in the network. Our main result shows that the sample complexity of PAC learning this class can be bounded by $O (w\log(T/\sigma))$. For the non-noisy version of the same class (i.e., $\sigma=0$), we prove a lower bound of $\Omega (wT)$ for the sample complexity. Our results indicate an exponential gap in the dependence of sample complexity on $T$ for noisy versus non-noisy networks. Moreover, given the mild logarithmic dependence of the upper bound on $1/\sigma$, this gap still holds even for numerically negligible values of $\sigma$.
Benefits of Additive Noise in Composing Classes with Bounded Capacity
Jun 14, 2022
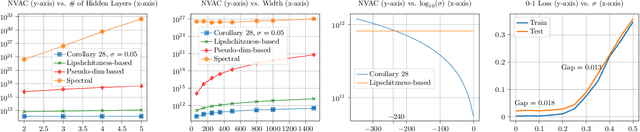

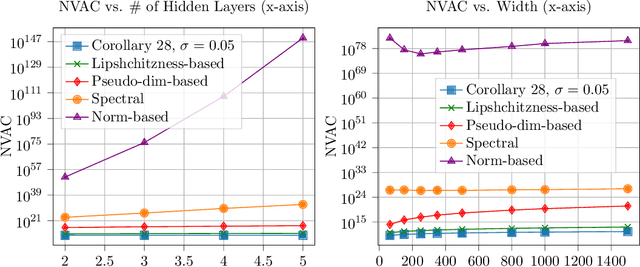
We observe that given two (compatible) classes of functions $\mathcal{F}$ and $\mathcal{H}$ with small capacity as measured by their uniform covering numbers, the capacity of the composition class $\mathcal{H} \circ \mathcal{F}$ can become prohibitively large or even unbounded. We then show that adding a small amount of Gaussian noise to the output of $\mathcal{F}$ before composing it with $\mathcal{H}$ can effectively control the capacity of $\mathcal{H} \circ \mathcal{F}$, offering a general recipe for modular design. To prove our results, we define new notions of uniform covering number of random functions with respect to the total variation and Wasserstein distances. We instantiate our results for the case of multi-layer sigmoid neural networks. Preliminary empirical results on MNIST dataset indicate that the amount of noise required to improve over existing uniform bounds can be numerically negligible (i.e., element-wise i.i.d. Gaussian noise with standard deviation $10^{-240}$). The source codes are available at https://github.com/fathollahpour/composition_noise.