 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computational Approach to Measuring the Semantic Divergence of Cognates
Dec 02, 2020
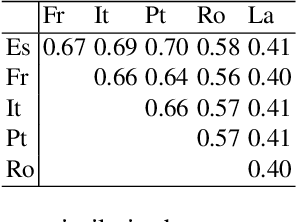
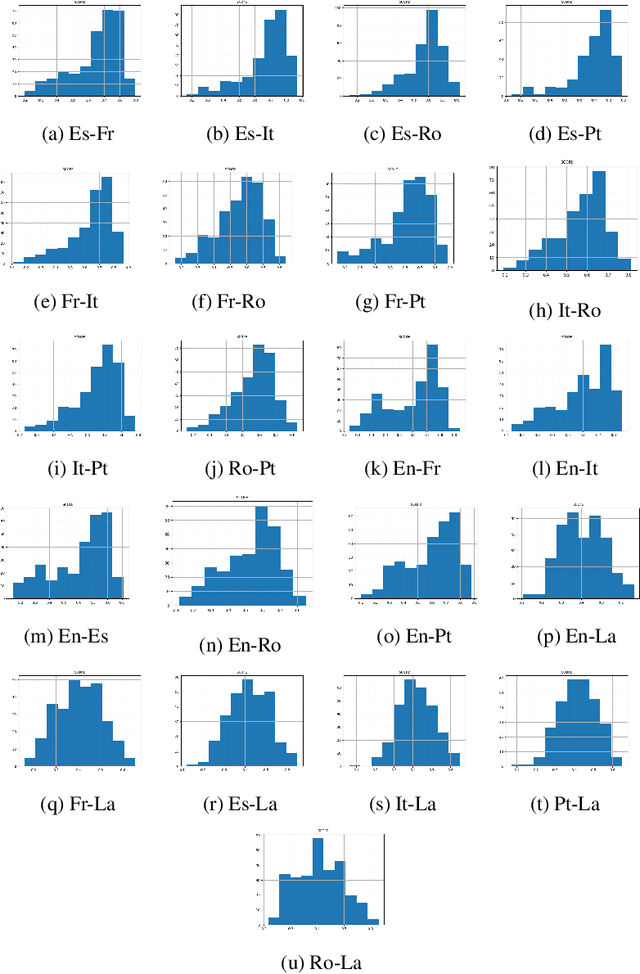

Meaning is the foundation stone of intercultural communication. Languages are continuously changing, and words shift their meanings for various reasons. Semantic divergence in related languages is a key concern of historical linguistics. In this paper we investigate semantic divergence across languages by measuring the semantic similarity of cognate sets in multiple languages. The method that we propose is based on cross-lingual word embeddings. In this paper we implement and evaluate our method on English and five Romance languages, but it can be extended easily to any language pair, requiring only large monolingual corpora for the involved languages and a small bilingual dictionary for the pair. This language-agnostic method facilitates a quantitative analysis of cognates divergence -- by computing degrees of semantic similarity between cognate pairs -- and provides insights for identifying false friends. As a second contribution, we formulate a straightforward method for detecting false friends, and introduce the notion of "soft false friend" and "hard false friend", as well as a measure of the degree of "falseness" of a false friends pair. Additionally, we propose an algorithm that can output suggestions for correcting false friends, which could result in a very helpful tool for language learning or translation.