 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Extraction of Fine-Grained Standardized Product Information from Unstructured Multilingual Web Data
Feb 23, 2023Extracting structured information from unstructured data is one of the key challenges in modern information retrieval applications, including e-commerce. Here, we demonstrate how recent advances in machine learning, combined with a recently published multilingual data set with standardized fine-grained product category information, enable robust product attribute extraction in challenging transfer learning settings. Our models can reliably predict product attributes across online shops, languages, or both. Furthermore, we show that our models can be used to match product taxonomies between online retailers.
GreenDB -- A Dataset and Benchmark for Extraction of Sustainability Information of Consumer Goods
Jul 29, 2022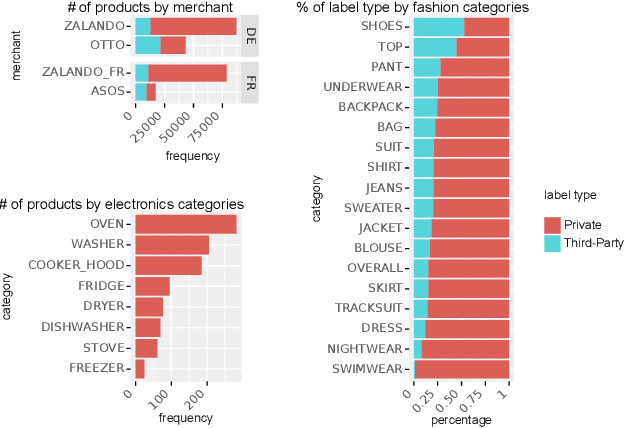
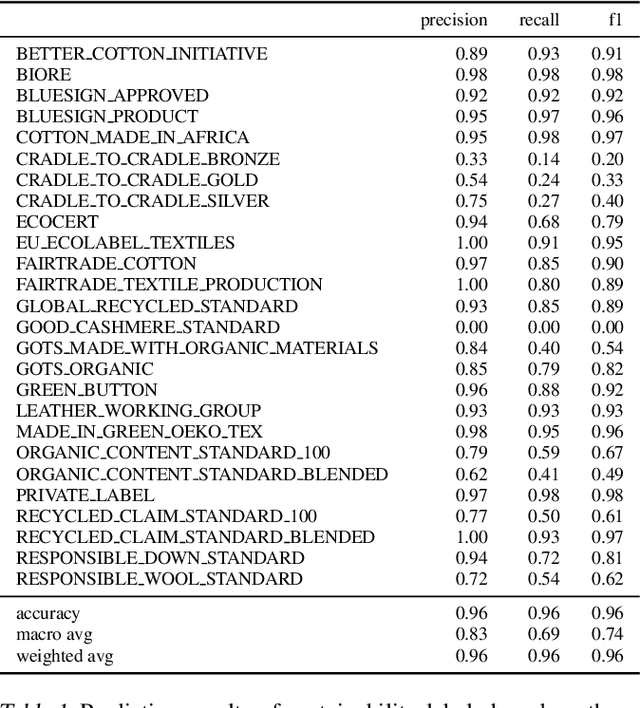
The production, shipping, usage, and disposal of consumer goods have a substantial impact on greenhouse gas emissions and the depletion of resources. Machine Learning (ML) can help to foster sustainable consumption patterns by accounting for sustainability aspects in product search or recommendations of modern retail platforms. However, the lack of large high quality publicly available product data with trustworthy sustainability information impedes the development of ML technology that can help to reach our sustainability goals. Here we present GreenDB, a database that collects products from European online shops on a weekly basis. As proxy for the products' sustainability, it relies on sustainability labels, which are evaluated by experts. The GreenDB schema extends the well-known schema.org Product definition and can be readily integrated into existing product catalogs. We present initial results demonstrating that ML models trained with our data can reliably (F1 score 96%) predict the sustainability label of products. These contributions can help to complement existing e-commerce experiences and ultimately encourage users to more sustainable consumption patterns.