 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Transferable Feature Extractors: Learning to Defend Pre-Trained Networks Against White Box Adversaries
Sep 14, 2022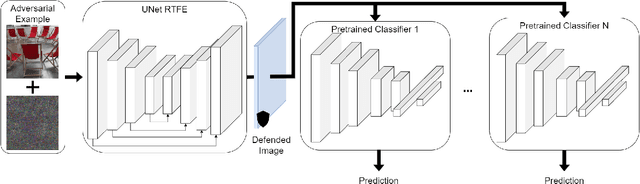
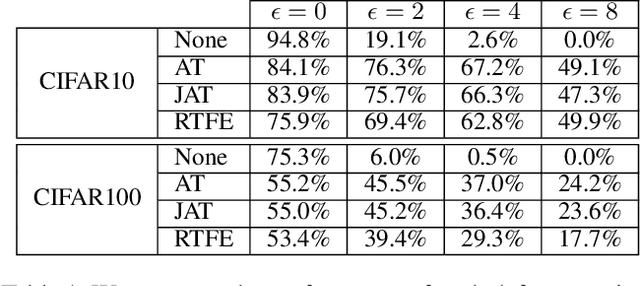

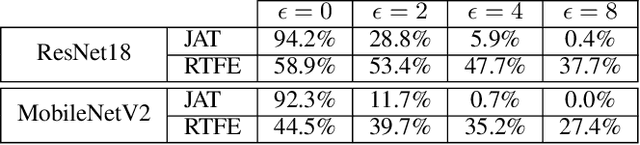
The widespread adoption of deep neural networks in computer vision applications has brought forth a significant interest in adversarial robustness. Existing research has shown that maliciously perturbed inputs specifically tailored for a given model (i.e., adversarial examples) can be successfully transferred to another independently trained model to induce prediction errors. Moreover, this property of adversarial examples has been attributed to features derived from predictive patterns in the data distribution. Thus, we are motivated to investigate the following question: Can adversarial defenses, like adversarial examples, be successfully transferred to other independently trained models? To this end, we propose a deep learning-based pre-processing mechanism, which we refer to as a robust transferable feature extractor (RTFE). After examining theoretical motivation and implications, we experimentally show that our method can provide adversarial robustness to multiple independently pre-trained classifiers that are otherwise ineffective against an adaptive white box adversary. Furthermore, we show that RTFEs can even provide one-shot adversarial robustness to models independently trained on different datasets.