 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Alzheimer's Disease Signatures by bridging EEG with Spiking Neural Networks and Biophysical Simulations
Jan 30, 2026As the prevalence of Alzheimer's disease (AD) rises, improving mechanistic insight from non-invasive biomarkers is increasingly critical. Recent work suggests that circuit-level brain alterations manifest as changes in electroencephalography (EEG) spectral features detectable by machine learning. However, conventional deep learning approaches for EEG-based AD detection are computationally intensive and mechanistically opaque. Spiking neural networks (SNNs) offer a biologically plausible and energy-efficient alternative, yet their application to AD diagnosis remains largely unexplored. We propose a neuro-bridge framework that links data-driven learning with minimal, biophysically grounded simulations, enabling bidirectional interpretation between machine learning signatures and circuit-level mechanisms in AD. Using resting-state clinical EEG, we train an SNN classifier that achieves competitive performance (AUC = 0.839) and identifies the aperiodic 1/f slope as a key discriminative marker. The 1/f slope reflects excitation-inhibition balance. To interpret this mechanistically, we construct spiking network simulations in which inhibitory-to-excitatory synaptic ratios are systematically varied to emulate healthy, mild cognitive impairment, and AD-like states. Using both membrane potential-based and synaptic current-based EEG proxies, we reproduce empirical spectral slowing and altered alpha organization. Incorporating empirical functional connectivity priors into multi-subnetwork simulations further enhances spectral differentiation, demonstrating that large-scale network topology constrains EEG signatures more strongly than excitation-inhibition balance alone. Overall, this neuro-bridge approach connects SNN-based classification with interpretable circuit simulations, advancing mechanistic understanding of EEG biomarkers while enabling scalable, explainable AD detection.
Prediction and Causality of functional MRI and synthetic signal using a Zero-Shot Time-Series Foundation Model
Sep 15, 2025Time-series forecasting and causal discovery are central in neuroscience, as predicting brain activity and identifying causal relationships between neural populations and circuits can shed light on the mechanisms underlying cognition and disease. With the rise of foundation models, an open question is how they compare to traditional methods for brain signal forecasting and causality analysis, and whether they can be applied in a zero-shot setting. In this work, we evaluate a foundation model against classical methods for inferring directional interactions from spontaneous brain activity measured with functional magnetic resonance imaging (fMRI) in humans. Traditional approaches often rely on Wiener-Granger causality. We tested the forecasting ability of the foundation model in both zero-shot and fine-tuned settings, and assessed causality by comparing Granger-like estimates from the model with standard Granger causality. We validated the approach using synthetic time series generated from ground-truth causal models, including logistic map coupling and Ornstein-Uhlenbeck processes. The foundation model achieved competitive zero-shot forecasting fMRI time series (mean absolute percentage error of 0.55 in controls and 0.27 in patients). Although standard Granger causality did not show clear quantitative differences between models, the foundation model provided a more precise detection of causal interactions. Overall, these findings suggest that foundation models offer versatility, strong zero-shot performance, and potential utility for forecasting and causal discovery in time-series data.
SharpXR: Structure-Aware Denoising for Pediatric Chest X-Rays
Aug 11, 2025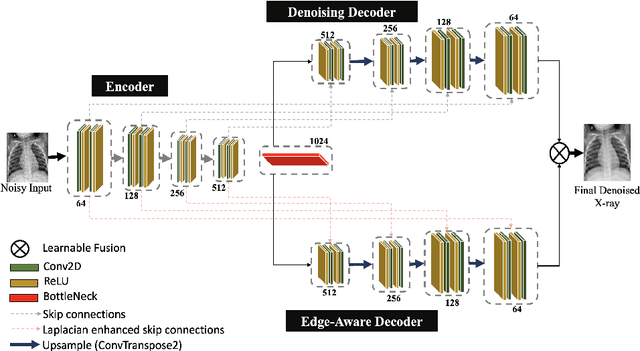



Pediatric chest X-ray imaging is essential for early diagnosis, particularly in low-resource settings where advanced imaging modalities are often inaccessible. Low-dose protocols reduce radiation exposure in children but introduce substantial noise that can obscure critical anatomical details. Conventional denoising methods often degrade fine details, compromising diagnostic accuracy. In this paper, we present SharpXR, a structure-aware dual-decoder U-Net designed to denoise low-dose pediatric X-rays while preserving diagnostically relevant features. SharpXR combines a Laplacian-guided edge-preserving decoder with a learnable fusion module that adaptively balances noise suppression and structural detail retention. To address the scarcity of paired training data, we simulate realistic Poisson-Gaussian noise on the Pediatric Pneumonia Chest X-ray dataset. SharpXR outperforms state-of-the-art baselines across all evaluation metrics while maintaining computational efficiency suitable for resource-constrained settings. SharpXR-denoised images improved downstream pneumonia classification accuracy from 88.8% to 92.5%, underscoring its diagnostic value in low-resource pediatric care.
End-to-end Stroke imaging analysis, using reservoir computing-based effective connectivity, and interpretable Artificial intelligence
Jul 17, 2024In this paper, we propose a reservoir computing-based and directed graph analysis pipeline. The goal of this pipeline is to define an efficient brain representation for connectivity in stroke data derived from magnetic resonance imaging. Ultimately, this representation is used within a directed graph convolutional architecture and investigated with explainable artificial intelligence (AI) tools. Stroke is one of the leading causes of mortality and morbidity worldwide, and it demands precise diagnostic tools for timely intervention and improved patient outcomes. Neuroimaging data, with their rich structural and functional information, provide a fertile ground for biomarker discovery. However, the complexity and variability of information flow in the brain requires advanced analysis, especially if we consider the case of disrupted networks as those given by the brain connectome of stroke patients. To address the needs given by this complex scenario we proposed an end-to-end pipeline. This pipeline begins with reservoir computing causality, to define effective connectivity of the brain. This allows directed graph network representations which have not been fully investigated so far by graph convolutional network classifiers. Indeed, the pipeline subsequently incorporates a classification module to categorize the effective connectivity (directed graphs) of brain networks of patients versus matched healthy control. The classification led to an area under the curve of 0.69 with the given heterogeneous dataset. Thanks to explainable tools, an interpretation of disrupted networks across the brain networks was possible. This elucidates the effective connectivity biomarker's contribution to stroke classification, fostering insights into disease mechanisms and treatment responses.
Synergistic eigenanalysis of covariance and Hessian matrices for enhanced binary classification
Feb 14, 2024Covariance and Hessian matrices have been analyzed separately in the literature for classification problems. However, integrating these matrices has the potential to enhance their combined power in improving classification performance. We present a novel approach that combines the eigenanalysis of a covariance matrix evaluated on a training set with a Hessian matrix evaluated on a deep learning model to achieve optimal class separability in binary classification tasks. Our approach is substantiated by formal proofs that establish its capability to maximize between-class mean distance and minimize within-class variances. By projecting data into the combined space of the most relevant eigendirections from both matrices, we achieve optimal class separability as per the linear discriminant analysis (LDA) criteria. Empirical validation across neural and health datasets consistently supports our theoretical framework and demonstrates that our method outperforms established methods. Our method stands out by addressing both LDA criteria, unlike PCA and the Hessian method, which predominantly emphasize one criterion each. This comprehensive approach captures intricate patterns and relationships, enhancing classification performance. Furthermore, through the utilization of both LDA criteria, our method outperforms LDA itself by leveraging higher-dimensional feature spaces, in accordance with Cover's theorem, which favors linear separability in higher dimensions. Our method also surpasses kernel-based methods and manifold learning techniques in performance. Additionally, our approach sheds light on complex DNN decision-making, rendering them comprehensible within a 2D space.
Style transfer between Microscopy and Magnetic Resonance Imaging via Generative Adversarial Network in small sample size settings
Oct 16, 2023Cross-modal augmentation of Magnetic Resonance Imaging (MRI) and microscopic imaging based on the same tissue samples is promising because it can allow histopathological analysis in the absence of an underlying invasive biopsy procedure. Here, we tested a method for generating microscopic histological images from MRI scans of the corpus callosum using conditional generative adversarial network (cGAN) architecture. To our knowledge, this is the first multimodal translation of the brain MRI to histological volumetric representation of the same sample. The technique was assessed by training paired image translation models taking sets of images from MRI scans and microscopy. The use of cGAN for this purpose is challenging because microscopy images are large in size and typically have low sample availability. The current work demonstrates that the framework reliably synthesizes histology images from MRI scans of corpus callosum, emphasizing the network's ability to train on high resolution histologies paired with relatively lower-resolution MRI scans. With the ultimate goal of avoiding biopsies, the proposed tool can be used for educational purposes.
* 2023 IEEE International Conference on Image Processing (ICIP)
Establishing Trust in ChatGPT BioMedical Generated Text: An Ontology-Based Knowledge Graph to Validate Disease-Symptom Links
Aug 07, 2023Methods: Through an innovative approach, we construct ontology-based knowledge graphs from authentic medical literature and AI-generated content. Our goal is to distinguish factual information from unverified data. We compiled two datasets: one from biomedical literature using a "human disease and symptoms" query, and another generated by ChatGPT, simulating articles. With these datasets (PubMed and ChatGPT), we curated 10 sets of 250 abstracts each, selected randomly with a specific seed. Our method focuses on utilizing disease ontology (DOID) and symptom ontology (SYMP) to build knowledge graphs, robust mathematical models that facilitate unbiased comparisons. By employing our fact-checking algorithms and network centrality metrics, we conducted GPT disease-symptoms link analysis to quantify the accuracy of factual knowledge amid noise, hypotheses, and significant findings. Results: The findings obtained from the comparison of diverse ChatGPT knowledge graphs with their PubMed counterparts revealed some interesting observations. While PubMed knowledge graphs exhibit a wealth of disease-symptom terms, it is surprising to observe that some ChatGPT graphs surpass them in the number of connections. Furthermore, some GPT graphs are demonstrating supremacy of the centrality scores, especially for the overlapping nodes. This striking contrast indicates the untapped potential of knowledge that can be derived from AI-generated content, awaiting verification. Out of all the graphs, the factual link ratio between any two graphs reached its peak at 60%. Conclusions: An intriguing insight from our findings was the striking number of links among terms in the knowledge graph generated from ChatGPT datasets, surpassing some of those in its PubMed counterpart. This early discovery has prompted further investigation using universal network metrics to unveil the new knowledge the links may hold.