 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanglaNLP at BLP-2023 Task 2: Benchmarking different Transformer Models for Sentiment Analysis of Bangla Social Media Posts
Oct 18, 2023
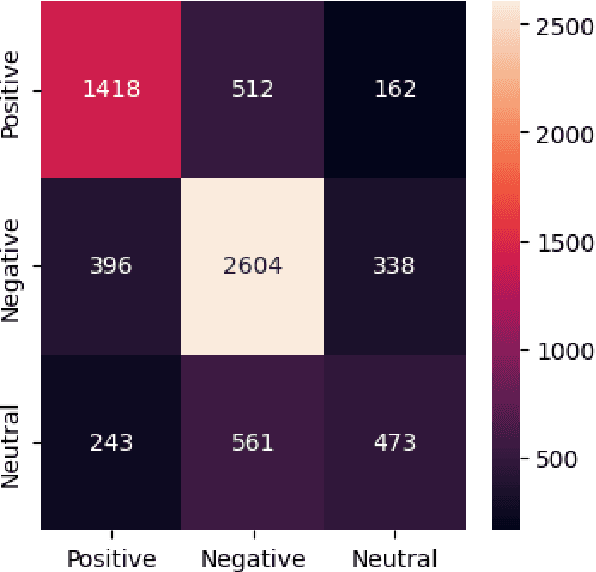

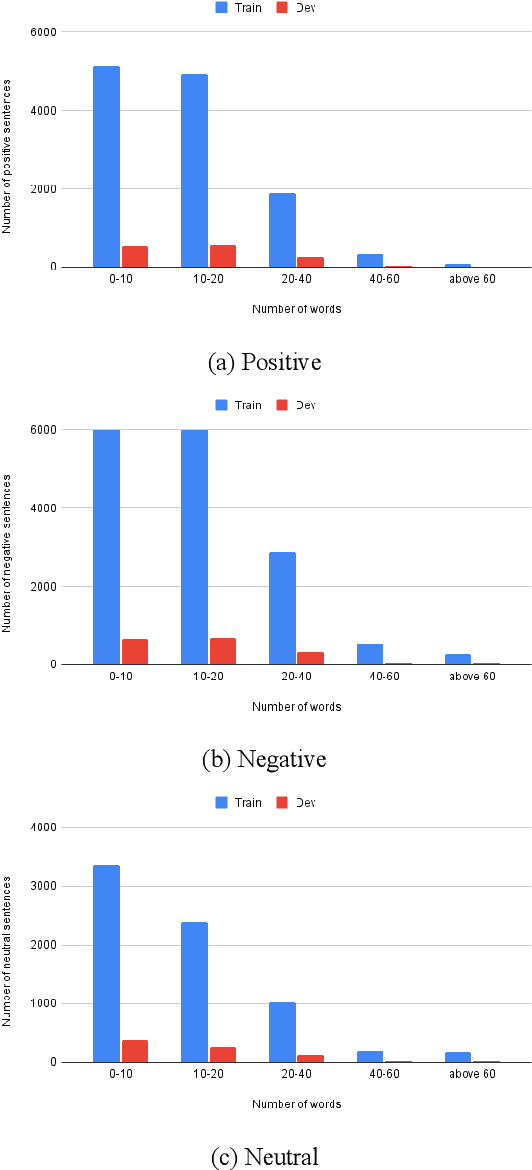
Bangla is the 7th most widely spoken language globally, with a staggering 234 million native speakers primarily hailing from India and Bangladesh. This morphologically rich language boasts a rich literary tradition, encompassing diverse dialects and language-specific challenges. Despite its linguistic richness and history, Bangla remains categorized as a low-resource language within the natural language processing (NLP) and speech community. This paper presents our submission to Task 2 (Sentiment Analysis of Bangla Social Media Posts) of the BLP Workshop. We experiment with various Transformer-based architectures to solve this task. Our quantitative results show that transfer learning really helps in better learning of the models in this low-resource language scenario. This becomes evident when we further finetune a model which has already been finetuned on twitter data for sentiment analysis task and that finetuned model performs the best among all other models. We also perform a detailed error analysis where we find some instances where ground truth labels need to be relooked at. We obtain a micro-F1 of 67.02\% on the test set and our performance in this shared task is ranked at 21 in the leaderboard.
BanglaNLP at BLP-2023 Task 1: Benchmarking different Transformer Models for Violence Inciting Text Detection in Bengali
Oct 16, 2023



This paper presents the system that we have developed while solving this shared task on violence inciting text detection in Bangla. We explain both the traditional and the recent approaches that we have used to make our models learn. Our proposed system helps to classify if the given text contains any threat. We studied the impact of data augmentation when there is a limited dataset available. Our quantitative results show that finetuning a multilingual-e5-base model performed the best in our task compared to other transformer-based architectures. We obtained a macro F1 of 68.11\% in the test set and our performance in this shared task is ranked at 23 in the leaderboard.