 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the gap between Human Action Recognition and Online Action Detection
Jan 21, 2021
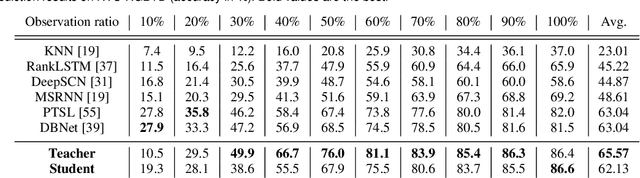


Action recognition, early prediction, and online action detection are complementary disciplines that are often studied independently. Most online action detection networks use a pre-trained feature extractor, which might not be optimal for its new task. We address the task-specific feature extraction with a teacher-student framework between the aforementioned disciplines, and a novel training strategy. Our network, Online Knowledge Distillation Action Detection network (OKDAD), embeds online early prediction and online temporal segment proposal subnetworks in parallel. Low interclass and high intraclass similarity are encouraged during teacher training. Knowledge distillation to the OKDAD network is ensured via layer reuse and cosine similarity between teacher-student feature vectors. Layer reuse and similarity learning significantly improve our baseline which uses a generic feature extractor. We evaluate our framework on infrared videos from two popular datasets, NTU RGB+D (action recognition, early prediction) and PKU MMD (action detection). Unlike previous attempts on those datasets, our student networks perform without any knowledge of the future. Even with this added difficulty, we achieve state-of-the-art results on both datasets. Moreover, our networks use infrared from RGB-D cameras, which we are the first to use for online action detection, to our knowledge.
Infrared and 3D skeleton feature fusion for RGB-D action recognition
Feb 28, 2020
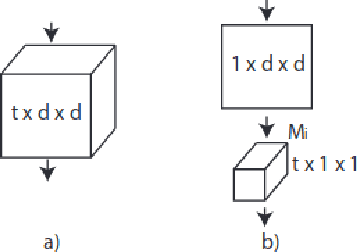
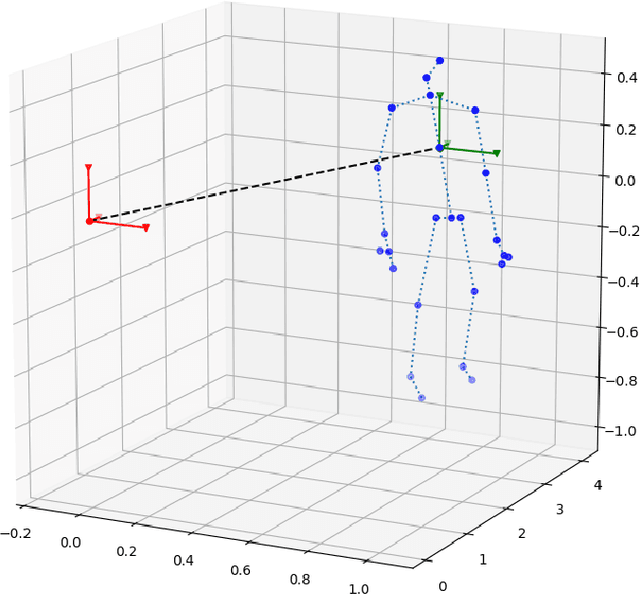
A challenge of skeleton-based action recognition is the difficulty to classify actions with similar motions and object-related actions. Visual clues from other streams help in that regard. RGB data are sensible to illumination conditions, thus unusable in the dark. To alleviate this issue and still benefit from a visual stream, we propose a modular network (FUSION) combining skeleton and infrared data. A 2D convolutional neural network (CNN) is used as a pose module to extract features from skeleton data. A 3D CNN is used as an infrared module to extract visual cues from videos. Both feature vectors are then concatenated and exploited conjointly using a multilayer perceptron (MLP). Skeleton data also condition the infrared videos, providing a crop around the performing subjects and thus virtually focusing the attention of the infrared module. Ablation studies show that using pre-trained networks on other large scale datasets as our modules and data augmentation yield considerable improvements on the action classification accuracy. The strong contribution of our cropping strategy is also demonstrated. We evaluate our method on the NTU RGB+D dataset, the largest dataset for human action recognition from depth cameras, and report state-of-the-art performances.