 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow communicatively optimal are exact numeral systems? Once more on lexicon size and morphosyntactic complexity
Feb 23, 2026Recent research argues that exact recursive numeral systems optimize communicative efficiency by balancing a tradeoff between the size of the numeral lexicon and the average morphosyntactic complexity (roughly length in morphemes) of numeral terms. We argue that previous studies have not characterized the data in a fashion that accounts for the degree of complexity languages display. Using data from 52 genetically diverse languages and an annotation scheme distinguishing between predictable and unpredictable allomorphy (formal variation), we show that many of the world's languages are decisively less efficient than one would expect. We discuss the implications of our findings for the study of numeral systems and linguistic evolution more generally.
Annotating and Inferring Compositional Structures in Numeral Systems Across Languages
Mar 04, 2025



Numeral systems across the world's languages vary in fascinating ways, both regarding their synchronic structure and the diachronic processes that determined how they evolved in their current shape. For a proper comparison of numeral systems across different languages, however, it is important to code them in a standardized form that allows for the comparison of basic properties. Here, we present a simple but effective coding scheme for numeral annotation, along with a workflow that helps to code numeral systems in a computer-assisted manner, providing sample data for numerals from 1 to 40 in 25 typologically diverse languages. We perform a thorough analysis of the sample, focusing on the systematic comparison between the underlying and the surface morphological structure. We further experiment with automated models for morpheme segmentation, where we find allomorphy as the major reason for segmentation errors. Finally, we show that subword tokenization algorithms are not viable for discovering morphemes in low-resource scenarios.
Everybody Likes to Sleep: A Computer-Assisted Comparison of Object Naming Data from 30 Languages
Jan 14, 2025
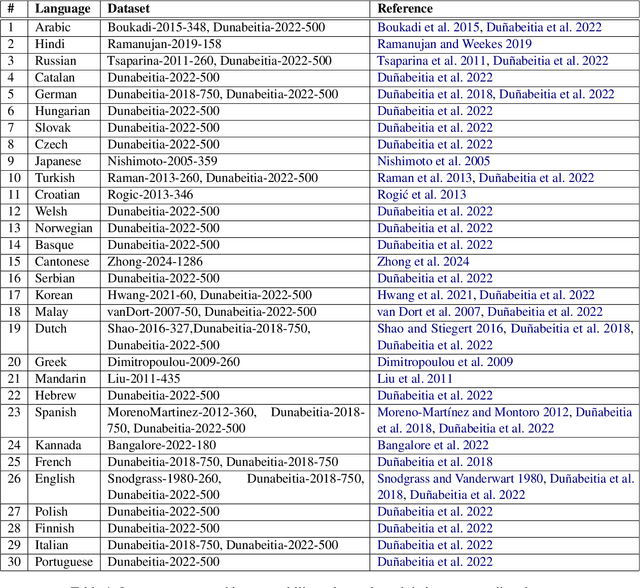
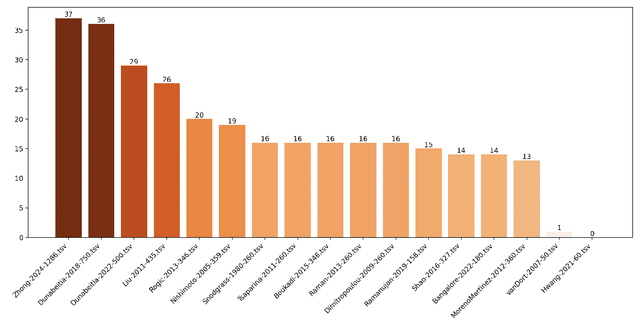
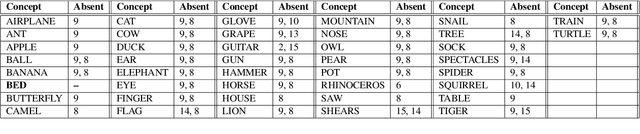
Object naming - the act of identifying an object with a word or a phrase - is a fundamental skill in interpersonal communication, relevant to many disciplines, such as psycholinguistics, cognitive linguistics, or language and vision research. Object naming datasets, which consist of concept lists with picture pairings, are used to gain insights into how humans access and select names for objects in their surroundings and to study the cognitive processes involved in converting visual stimuli into semantic concepts. Unfortunately, object naming datasets often lack transparency and have a highly idiosyncratic structure. Our study tries to make current object naming data transparent and comparable by using a multilingual, computer-assisted approach that links individual items of object naming lists to unified concepts. Our current sample links 17 object naming datasets that cover 30 languages from 10 different language families. We illustrate how the comparative dataset can be explored by searching for concepts that recur across the majority of datasets and comparing the conceptual spaces of covered object naming datasets with classical basic vocabulary lists from historical linguistics and linguistic typology. Our findings can serve as a basis for enhancing cross-linguistic object naming research and as a guideline for future studies dealing with object naming tasks.