 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Enhanced Indexing And Ranking Technique On The Semantic Web
Nov 29, 2011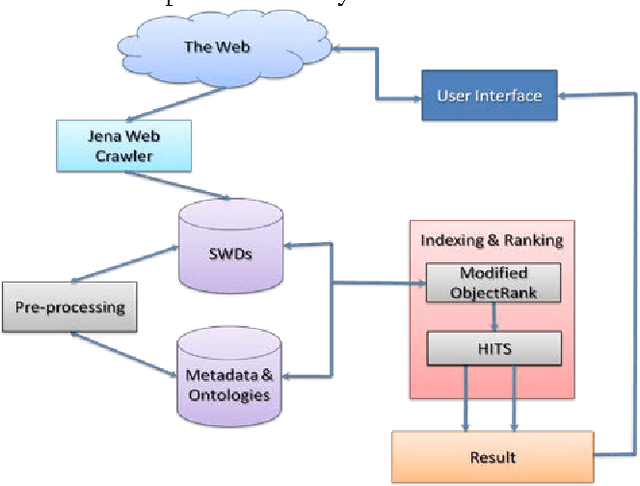
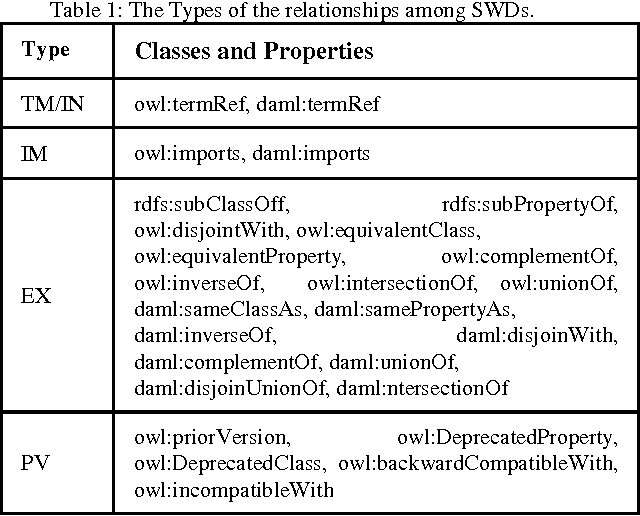
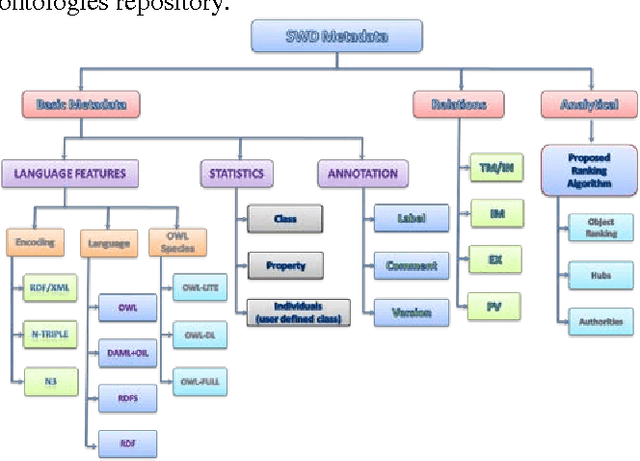
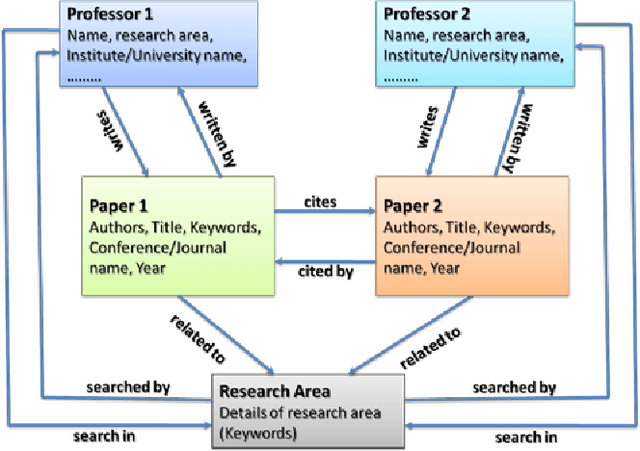
With the fast growth of the Internet, more and more information is available on the Web. The Semantic Web has many features which cannot be handled by using the traditional search engines. It extracts metadata for each discovered Web documents in RDF or OWL formats, and computes relations between documents. We proposed a hybrid indexing and ranking technique for the Semantic Web which finds relevant documents and computes the similarity among a set of documents. First, it returns with the most related document from the repository of Semantic Web Documents (SWDs) by using a modified version of the ObjectRank technique. Then, it creates a sub-graph for the most related SWDs. Finally, It returns the hubs and authorities of these document by using the HITS algorithm. Our technique increases the quality of the results and decreases the execution time of processing the user's query.
* 8 pages, 7 figures