 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAROLA: A Modular Layered Architecture for Scaled Autonomous Racing
Feb 02, 2026Autonomous racing has advanced rapidly, particularly on scaled platforms, and software stacks must evolve accordingly. In this work, AROLA is introduced as a modular, layered software architecture in which fragmented and monolithic designs are reorganized into interchangeable layers and components connected through standardized ROS 2 interfaces. The autonomous-driving pipeline is decomposed into sensing, pre-processing, perception, localization and mapping, planning, behavior, control, and actuation, enabling rapid module replacement and objective benchmarking without reliance on custom message definitions. To support consistent performance evaluation, a Race Monitor framework is introduced as a lightweight system through which lap timing, trajectory quality, and computational load are logged in real time and standardized post-race analyses are generated. AROLA is validated in simulation and on hardware using the RoboRacer platform, including deployment at the 2025 RoboRacer IV25 competition. Together, AROLA and Race Monitor demonstrate that modularity, transparent interfaces, and systematic evaluation can accelerate development and improve reproducibility in scaled autonomous racing.
From Prompts to Pavement: LMMs-based Agentic Behavior-Tree Generation Framework for Autonomous Vehicles
Jan 18, 2026Autonomous vehicles (AVs) require adaptive behavior planners to navigate unpredictable, real-world environments safely. Traditional behavior trees (BTs) offer structured decision logic but are inherently static and demand labor-intensive manual tuning, limiting their applicability at SAE Level 5 autonomy. This paper presents an agentic framework that leverages large language models (LLMs) and multi-modal vision models (LVMs) to generate and adapt BTs on the fly. A specialized Descriptor agent applies chain-of-symbols prompting to assess scene criticality, a Planner agent constructs high-level sub-goals via in-context learning, and a Generator agent synthesizes executable BT sub-trees in XML format. Integrated into a CARLA+Nav2 simulation, our system triggers only upon baseline BT failure, demonstrating successful navigation around unexpected obstacles (e.g., street blockage) with no human intervention. Compared to a static BT baseline, this approach is a proof-of-concept that extends to diverse driving scenarios.
Khattat: Enhancing Readability and Concept Representation of Semantic Typography
Oct 01, 2024Designing expressive typography that visually conveys a word's meaning while maintaining readability is a complex task, known as semantic typography. It involves selecting an idea, choosing an appropriate font, and balancing creativity with legibility. We introduce an end-to-end system that automates this process. First, a Large Language Model (LLM) generates imagery ideas for the word, useful for abstract concepts like freedom. Then, the FontCLIP pre-trained model automatically selects a suitable font based on its semantic understanding of font attributes. The system identifies optimal regions of the word for morphing and iteratively transforms them using a pre-trained diffusion model. A key feature is our OCR-based loss function, which enhances readability and enables simultaneous stylization of multiple characters. We compare our method with other baselines, demonstrating great readability enhancement and versatility across multiple languages and writing scripts.
Deterministic Guided LiDAR Depth Map Completion
Jun 14, 2021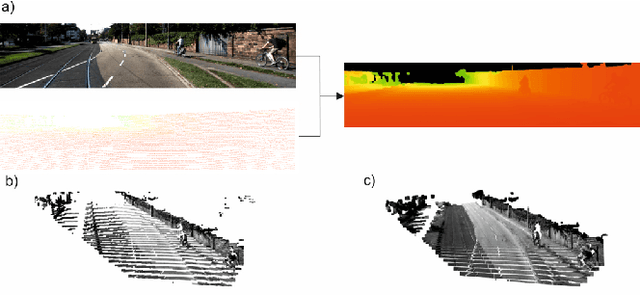


Accurate dense depth estimation is crucial for autonomous vehicles to analyze their environment. This paper presents a non-deep learning-based approach to densify a sparse LiDAR-based depth map using a guidance RGB image. To achieve this goal the RGB image is at first cleared from most of the camera-LiDAR misalignment artifacts. Afterward, it is over segmented and a plane for each superpixel is approximated. In the case a superpixel is not well represented by a plane, a plane is approximated for a convex hull of the most inlier. Finally, the pinhole camera model is used for the interpolation process and the remaining areas are interpolated. The evaluation of this work is executed using the KITTI depth completion benchmark, which validates the proposed work and shows that it outperforms the state-of-the-art non-deep learning-based methods, in addition to several deep learning-based methods.