 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Validity of Traditional Vulnerability Scoring Systems for Adversarial Attacks against LLMs
Dec 28, 2024
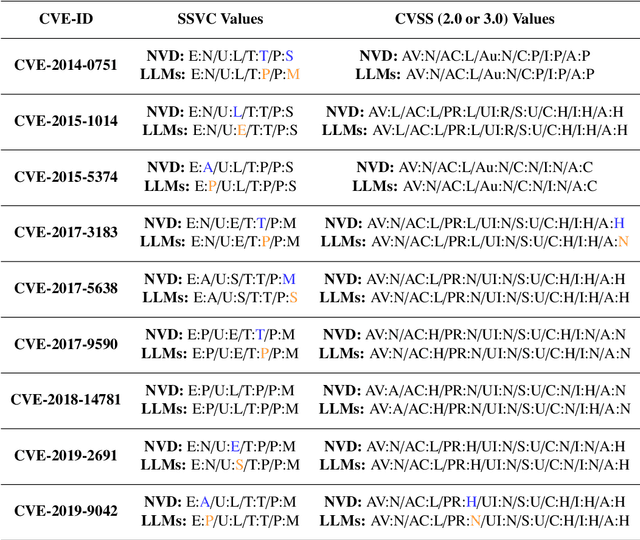


This research investigates the effectiveness of established vulnerability metrics, such as the Common Vulnerability Scoring System (CVSS), in evaluating attacks against Large Language Models (LLMs), with a focus on Adversarial Attacks (AAs). The study explores the influence of both general and specific metric factors in determining vulnerability scores, providing new perspectives on potential enhancements to these metrics. This study adopts a quantitative approach, calculating and comparing the coefficient of variation of vulnerability scores across 56 adversarial attacks on LLMs. The attacks, sourced from various research papers, and obtained through online databases, were evaluated using multiple vulnerability metrics. Scores were determined by averaging the values assessed by three distinct LLMs. The results indicate that existing scoring-systems yield vulnerability scores with minimal variation across different attacks, suggesting that many of the metric factors are inadequate for assessing adversarial attacks on LLMs. This is particularly true for context-specific factors or those with predefined value sets, such as those in CVSS. These findings support the hypothesis that current vulnerability metrics, especially those with rigid values, are limited in evaluating AAs on LLMs, highlighting the need for the development of more flexible, generalized metrics tailored to such attacks. This research offers a fresh analysis of the effectiveness and applicability of established vulnerability metrics, particularly in the context of Adversarial Attacks on Large Language Models, both of which have gained significant attention in recent years. Through extensive testing and calculations, the study underscores the limitations of these metrics and opens up new avenues for improving and refining vulnerability assessment frameworks specifically tailored for LLMs.
How to Design and Deliver Courses for Higher Education in the AI Era: Insights from Exam Data Analysis
Jul 22, 2023In this position paper, we advocate for the idea that courses and exams in the AI era have to be designed based on two factors: (1) the strengths and limitations of AI, and (2) the pedagogical educational objectives. Based on insights from the Delors report on education [1], we first address the role of education and recall the main objectives that educational institutes must strive to achieve independently of any technology. We then explore the strengths and limitations of AI, based on current advances in AI. We explain how courses and exams can be designed based on these strengths and limitations of AI, providing different examples in the IT, English, and Art domains. We show how we adopted a pedagogical approach that is inspired from the Socratic teaching method from January 2023 to May 2023. Then, we present the data analysis results of seven ChatGPT-authorized exams conducted between December 2022 and March 2023. Our exam data results show that there is no correlation between students' grades and whether or not they use ChatGPT to answer their exam questions. Finally, we present a new exam system that allows us to apply our pedagogical approach in the AI era.