 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Ensembles in an Adversarial Context: Improving Natural Accuracy
Feb 26, 2020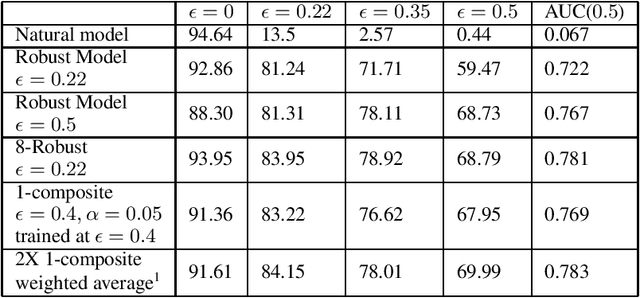
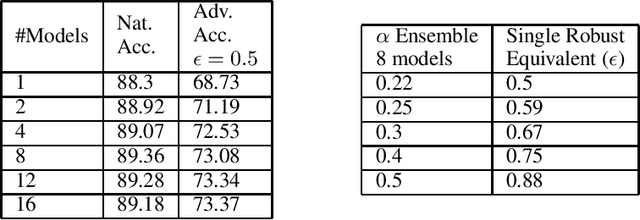
A necessary characteristic for the deployment of deep learning models in real world applications is resistance to small adversarial perturbations while maintaining accuracy on non-malicious inputs. While robust training provides models that exhibit better adversarial accuracy than standard models, there is still a significant gap in natural accuracy between robust and non-robust models which we aim to bridge. We consider a number of ensemble methods designed to mitigate this performance difference. Our key insight is that model trained to withstand small attacks, when ensembled, can often withstand significantly larger attacks, and this concept can in turn be leveraged to optimize natural accuracy. We consider two schemes, one that combines predictions from several randomly initialized robust models, and the other that fuses features from robust and standard models.
KnowBias: Detecting Political Polarity in Long Text Content
Sep 22, 2019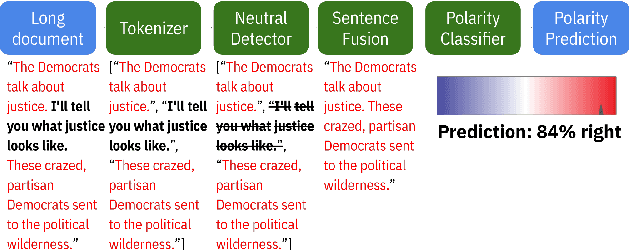
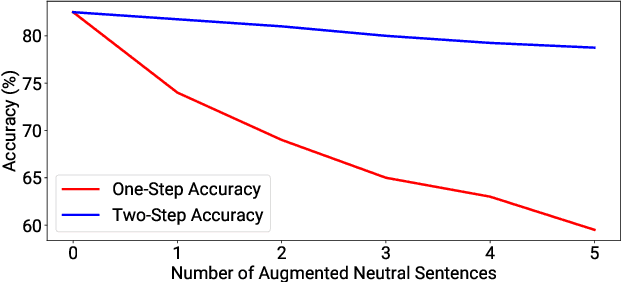
We introduce a classification scheme for detecting political bias in long text content such as newspaper opinion articles. Obtaining long text data and annotations at sufficient scale for training is difficult, but it is relatively easy to extract political polarity from tweets through their authorship; as such, we train on tweets and perform inference on articles. Universal sentence encoders and other existing methods that aim to address this domain-adaptation scenario deliver inaccurate and inconsistent predictions on articles, which we show is due to a difference in opinion concentration between tweets and articles. We propose a two-step classification scheme that utilizes a neutral detector trained on tweets to remove neutral sentences from articles in order to align opinion concentration and therefore improve accuracy on that domain. Our implementation is available for public use at https://knowbias.ml.
KnowBias: A Novel AI Method to Detect Polarity in Online Content
May 02, 2019



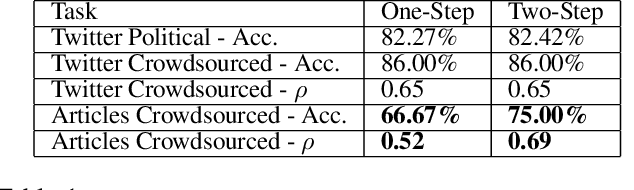
We introduce KnowBias, a system for detecting the degree of political bias in textual content such as social media posts and news articles. In the space of scalable text classification, a common problem is domain mismatch, where easily accessible training data (i.e., tweets) does not correspond in format to the desired testing domain (i.e., longer form article content). While universal text encoders such as word or sentence embeddings could be leveraged to train target agnostic classifiers, such schemes result in poor performance on long-form articles. Our key insight is that long-form articles are a mix of neutral and political sentences, while tweets are concentrated with opinion. We propose a two-step classification system that first automatically filters out neutral sentences from the input text document at evaluation time, and then the resulting text is input into a polarity classifier. We evaluate our two-step approach using a variety of test suites, including a set of tweets and long-form articles where annotations were crowd-sourced to decrease label noise, measuring accuracy and Spearman-rho rank correlation. In practice, KnowBias achieves a high accuracy of 86% (rho = 0.65) on these tweets and 75% (rho = 0.69) on long-form articles.