 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLesan -- Machine Translation for Low Resource Languages
Dec 15, 2021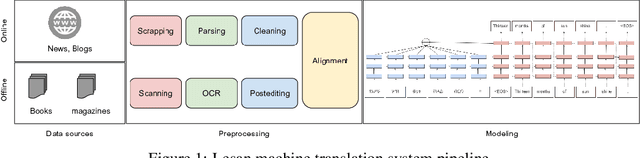

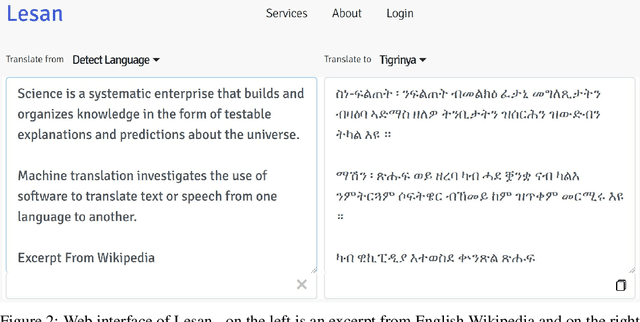
Millions of people around the world can not access content on the Web because most of the content is not readily available in their language. Machine translation (MT) systems have the potential to change this for many languages. Current MT systems provide very accurate results for high resource language pairs, e.g., German and English. However, for many low resource languages, MT is still under active research. The key challenge is lack of datasets to build these systems. We present Lesan, an MT system for low resource languages. Our pipeline solves the key bottleneck to low resource MT by leveraging online and offline sources, a custom OCR system for Ethiopic and an automatic alignment module. The final step in the pipeline is a sequence to sequence model that takes parallel corpus as input and gives us a translation model. Lesan's translation model is based on the Transformer architecture. After constructing a base model, back translation, is used to leverage monolingual corpora. Currently Lesan supports translation to and from Tigrinya, Amharic and English. We perform extensive human evaluation and show that Lesan outperforms state-of-the-art systems such as Google Translate and Microsoft Translator across all six pairs. Lesan is freely available and has served more than 10 million translations so far. At the moment, there are only 217 Tigrinya and 15,009 Amharic Wikipedia articles. We believe that Lesan will contribute towards democratizing access to the Web through MT for millions of people.
Evaluating Amharic Machine Translation
Mar 31, 2020Machine translation (MT) systems are now able to provide very accurate results for high resource language pairs. However, for many low resource languages, MT is still under active research. In this paper, we develop and share a dataset to automatically evaluate the quality of MT systems for Amharic. We compare two commercially available MT systems that support translation of Amharic to and from English to assess the current state of MT for Amharic. The BLEU score results show that the results for Amharic translation are promising but still low. We hope that this dataset will be useful to the research community both in academia and industry as a benchmark to evaluate Amharic MT systems.