 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Quantum-Classical Machine Learning for Sentiment Analysis
Oct 08, 2023



The collaboration between quantum computing and classical machine learning offers potential advantages in natural language processing, particularly in the sentiment analysis of human emotions and opinions expressed in large-scale datasets. In this work, we propose a methodology for sentiment analysis using hybrid quantum-classical machine learning algorithms. We investigate quantum kernel approaches and variational quantum circuit-based classifiers and integrate them with classical dimension reduction techniques such as PCA and Haar wavelet transform. The proposed methodology is evaluated using two distinct datasets, based on English and Bengali languages. Experimental results show that after dimensionality reduction of the data, performance of the quantum-based hybrid algorithms were consistent and better than classical methods.
Common human diseases prediction using machine learning based on survey data
Sep 22, 2022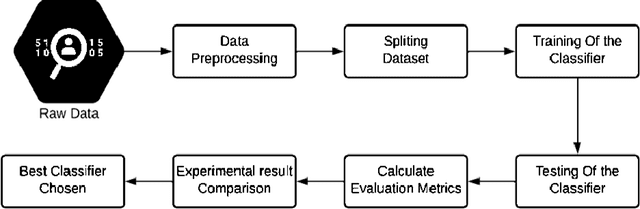
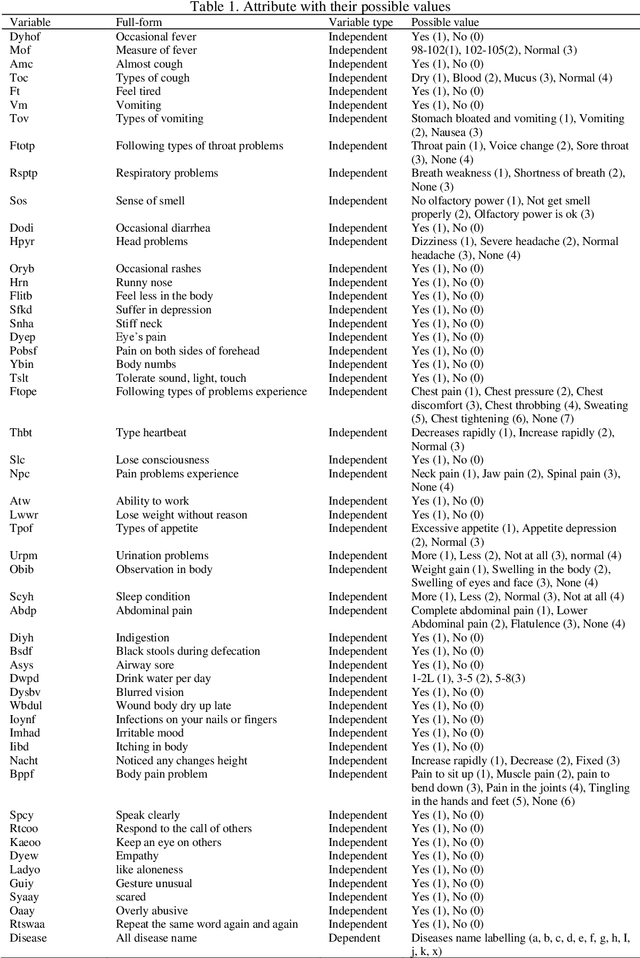
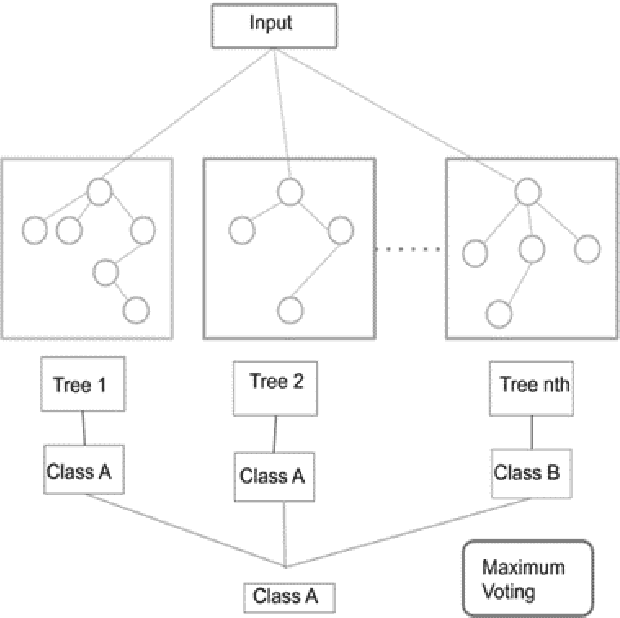
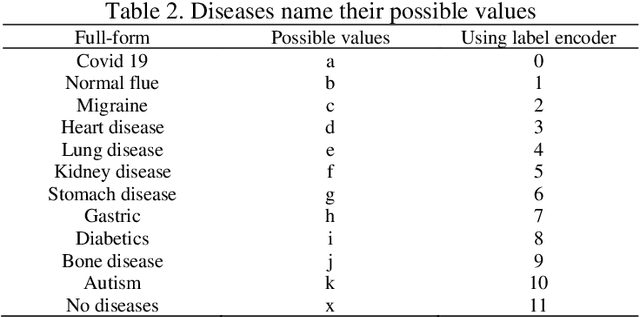
In this era, the moment has arrived to move away from disease as the primary emphasis of medical treatment. Although impressive, the multiple techniques that have been developed to detect the diseases. In this time, there are some types of diseases COVID-19, normal flue, migraine, lung disease, heart disease, kidney disease, diabetics, stomach disease, gastric, bone disease, autism are the very common diseases. In this analysis, we analyze disease symptoms and have done disease predictions based on their symptoms. We studied a range of symptoms and took a survey from people in order to complete the task. Several classification algorithms have been employed to train the model. Furthermore, performance evaluation matrices are used to measure the model's performance. Finally, we discovered that the part classifier surpasses the others.
An Insight into The Intricacies of Lingual Paraphrasing Pragmatic Discourse on The Purpose of Synonyms
Jun 07, 2022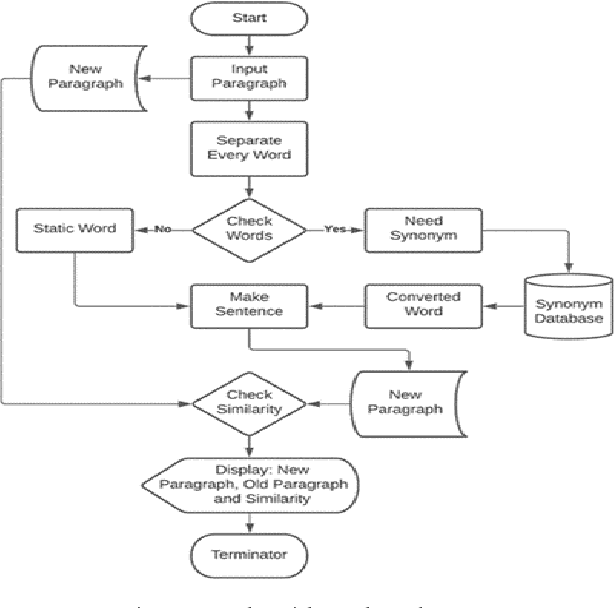



The term "paraphrasing" refers to the process of presenting the sense of an input text in a new way while preserving fluency. Scientific research distribution is gaining traction, allowing both rookie and experienced scientists to participate in their respective fields. As a result, there is now a massive demand for paraphrase tools that may efficiently and effectively assist scientists in modifying statements in order to avoid plagiarism. Natural Language Processing (NLP) is very much important in the realm of the process of document paraphrasing. We analyze and discuss existing studies on paraphrasing in the English language in this paper. Finally, we develop an algorithm to paraphrase any text document or paragraphs using WordNet and Natural Language Tool Kit (NLTK) and maintain "Using Synonyms" techniques to achieve our result. For 250 paragraphs, our algorithm achieved a paraphrase accuracy of 94.8%
An Opinion Mining of Text in COVID-19 Issues along with Comparative Study in ML, BERT & RNN
Jan 06, 2022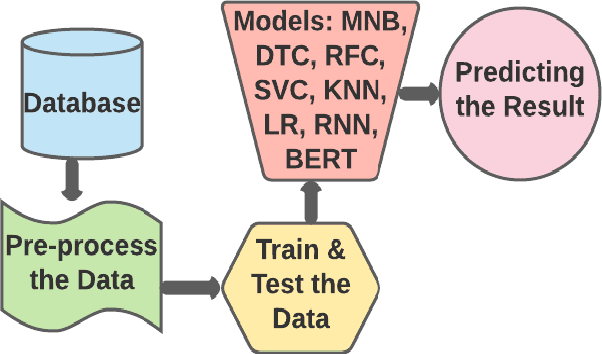
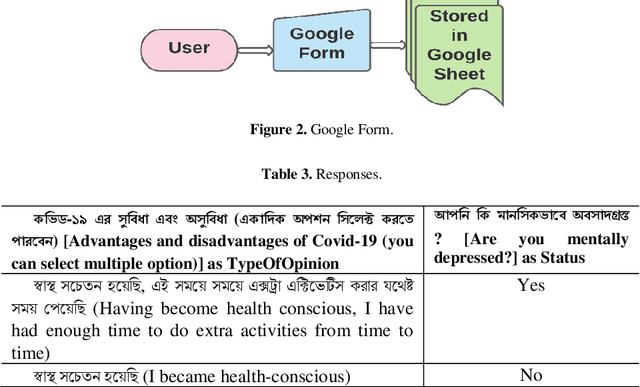
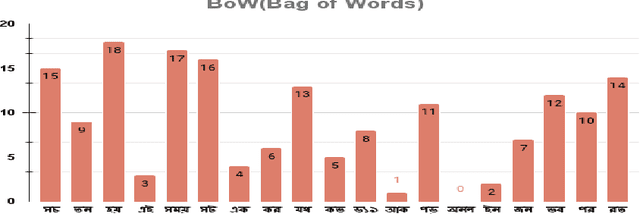
The global world is crossing a pandemic situation where this is a catastrophic outbreak of Respiratory Syndrome recognized as COVID-19. This is a global threat all over the 212 countries that people every day meet with mighty situations. On the contrary, thousands of infected people live rich in mountains. Mental health is also affected by this worldwide coronavirus situation. Due to this situation online sources made a communicative place that common people shares their opinion in any agenda. Such as affected news related positive and negative, financial issues, country and family crisis, lack of import and export earning system etc. different kinds of circumstances are recent trendy news in anywhere. Thus, vast amounts of text are produced within moments therefore, in subcontinent areas the same as situation in other countries and peoples opinion of text and situation also same but the language is different. This article has proposed some specific inputs along with Bangla text comments from individual sources which can assure the goal of illustration that machine learning outcome capable of building an assistive system. Opinion mining assistive system can be impactful in all language preferences possible. To the best of our knowledge, the article predicted the Bangla input text on COVID-19 issues proposed ML algorithms and deep learning models analysis also check the future reachability with a comparative analysis. Comparative analysis states a report on text prediction accuracy is 91% along with ML algorithms and 79% along with Deep Learning Models.
* 16 pages, 9 figures
Deep Learning Based Classification System For Recognizing Local Spinach
Jan 06, 2022
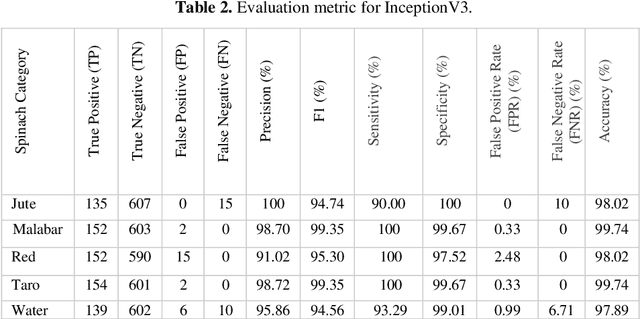
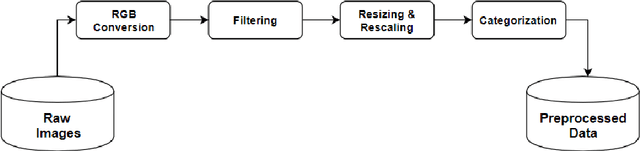
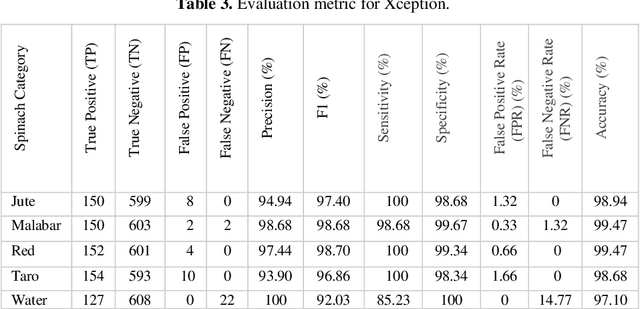
A deep learning model gives an incredible result for image processing by studying from the trained dataset. Spinach is a leaf vegetable that contains vitamins and nutrients. In our research, a Deep learning method has been used that can automatically identify spinach and this method has a dataset of a total of five species of spinach that contains 3785 images. Four Convolutional Neural Network (CNN) models were used to classify our spinach. These models give more accurate results for image classification. Before applying these models there is some preprocessing of the image data. For the preprocessing of data, some methods need to happen. Those are RGB conversion, filtering, resize & rescaling, and categorization. After applying these methods image data are pre-processed and ready to be used in the classifier algorithms. The accuracy of these classifiers is in between 98.68% - 99.79%. Among those models, VGG16 achieved the highest accuracy of 99.79%.
Transformer Based Bengali Chatbot Using General Knowledge Dataset
Nov 09, 2021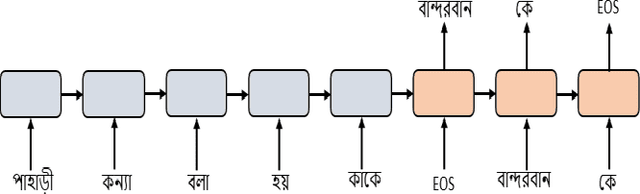
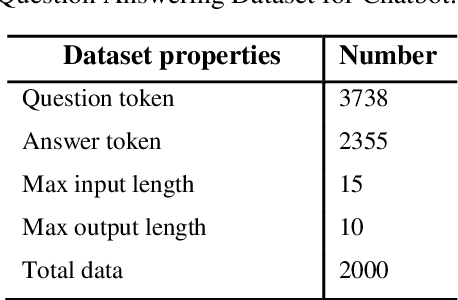
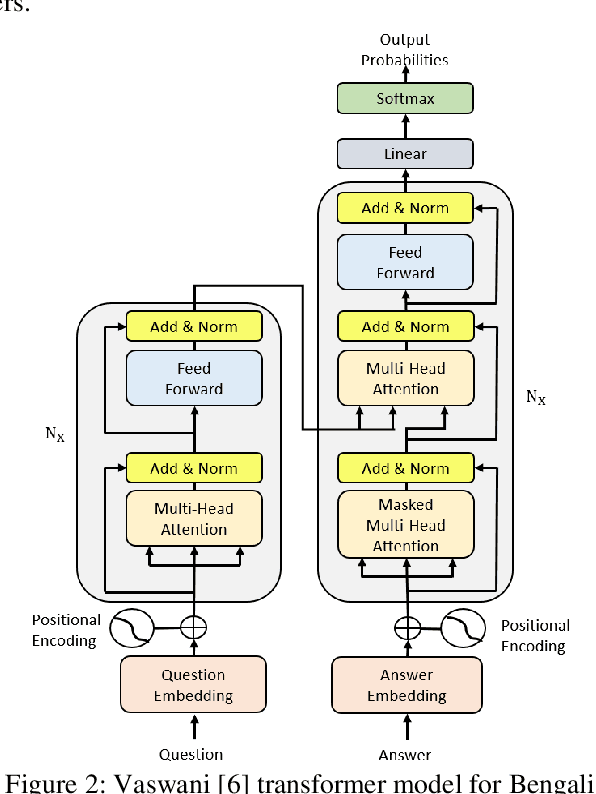
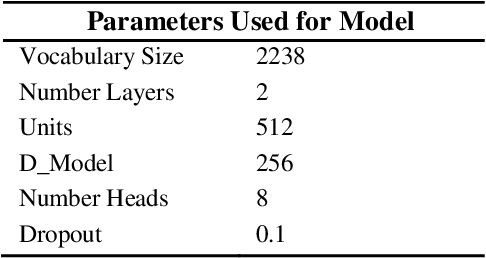
An AI chatbot provides an impressive response after learning from the trained dataset. In this decade, most of the research work demonstrates that deep neural models superior to any other model. RNN model regularly used for determining the sequence-related problem like a question and it answers. This approach acquainted with everyone as seq2seq learning. In a seq2seq model mechanism, it has encoder and decoder. The encoder embedded any input sequence, and the decoder embedded output sequence. For reinforcing the seq2seq model performance, attention mechanism added into the encoder and decoder. After that, the transformer model has introduced itself as a high-performance model with multiple attention mechanism for solving the sequence-related dilemma. This model reduces training time compared with RNN based model and also achieved state-of-the-art performance for sequence transduction. In this research, we applied the transformer model for Bengali general knowledge chatbot based on the Bengali general knowledge Question Answer (QA) dataset. It scores 85.0 BLEU on the applied QA data. To check the comparison of the transformer model performance, we trained the seq2seq model with attention on our dataset that scores 23.5 BLEU.