Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Unsupervised Adaptive Crowdsourcing
Oct 09, 2011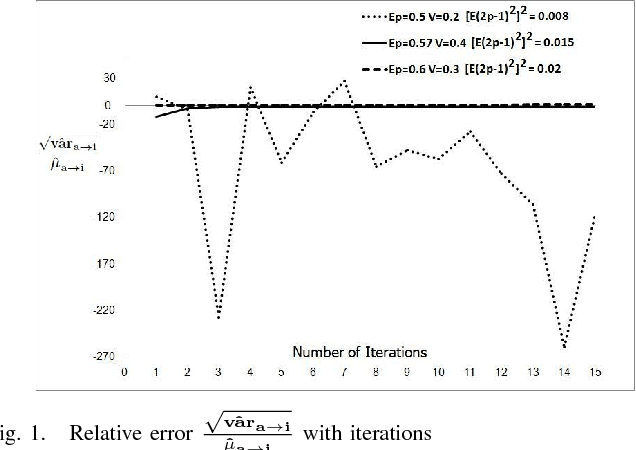
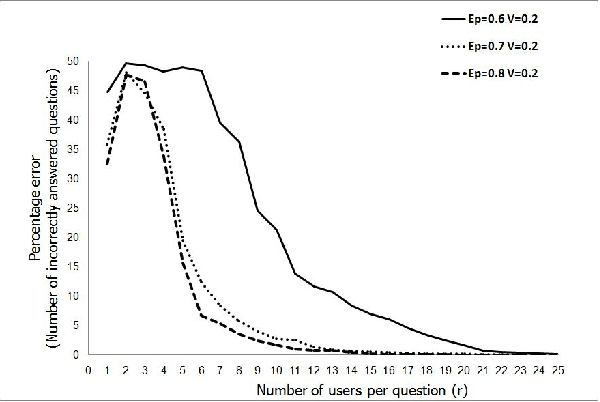
We consider unsupervised crowdsourcing performance based on the model wherein the responses of end-users are essentially rated according to how their responses correlate with the majority of other responses to the same subtasks/questions. In one setting, we consider an independent sequence of identically distributed crowdsourcing assignments (meta-tasks), while in the other we consider a single assignment with a large number of component subtasks. Both problems yield intuitive results in which the overall reliability of the crowd is a factor.
* Technical Report, 2 figures
Via