 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURMF: Uncertainty-aware Robust Multimodal Fusion for Multimodal Sarcasm Detection
Apr 08, 2026Multimodal sarcasm detection (MSD) aims to identify sarcastic intent from semantic incongruity between text and image. Although recent methods have improved MSD through cross-modal interaction and incongruity reasoning, they often assume that all modalities are equally reliable. In real-world social media, however, textual content may be ambiguous and visual content may be weakly relevant or even irrelevant, causing deterministic fusion to introduce noisy evidence and weaken robust reasoning. To address this issue, we propose Uncertainty-aware Robust Multimodal Fusion (URMF), a unified framework that explicitly models modality reliability during interaction and fusion. URMF first employs multi-head cross-attention to inject visual evidence into textual representations, followed by multi-head self-attention in the fused semantic space to enhance incongruity-aware reasoning. It then performs unified unimodal aleatoric uncertainty modeling over text, image, and interaction-aware latent representations by parameterizing each modality as a learnable Gaussian posterior. The estimated uncertainty is further used to dynamically regulate modality contributions during fusion, suppressing unreliable modalities and yielding a more robust joint representation. In addition, we design a joint training objective integrating task supervision, modality prior regularization, cross-modal distribution alignment, and uncertainty-driven self-sampling contrastive learning. Experiments on public MSD benchmarks show that URMF consistently outperforms strong unimodal, multimodal, and MLLM-based baselines, demonstrating the effectiveness of uncertainty-aware fusion for improving both accuracy and robustness.
MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Apr 06, 2026Current document parsing methods compete primarily on model architecture innovation, while systematic engineering of training data remains underexplored. Yet SOTA models of different architectures and parameter scales exhibit highly consistent failure patterns on the same set of hard samples, suggesting that the performance bottleneck stems from shared deficiencies in training data rather than architecture itself. Building on this finding, we present \minerupro, which advances the state of the art solely through data engineering and training strategy optimization while keeping the 1.2B-parameter architecture of \mineru completely fixed. At its core is a Data Engine co-designed around coverage, informativeness, and annotation accuracy: Diversity-and-Difficulty-Aware Sampling expands training data from under 10M to 65.5M samples while correcting distribution shift; Cross-Model Consistency Verification leverages output agreement among heterogeneous models to assess sample difficulty and generate reliable annotations; the Judge-and-Refine pipeline improves annotation quality for hard samples through render-then-verify iterative correction. A three-stage progressive training strategy -- large-scale pre-training, hard sample fine-tuning, and GRPO alignment -- sequentially exploits these data at different quality tiers. On the evaluation front, we fix element-matching biases in OmniDocBench~v1.5 and introduce a Hard subset, establishing the more discriminative OmniDocBench~v1.6 protocol. Without any architectural modification, \minerupro achieves 95.69 on OmniDocBench~v1.6, improving over the same-architecture baseline by 2.71 points and surpassing all existing methods including models with over 200$\times$ more parameters.
V2U4Real: A Real-world Large-scale Dataset for Vehicle-to-UAV Cooperative Perception
Mar 26, 2026Modern autonomous vehicle perception systems are often constrained by occlusions, blind spots, and limited sensing range. While existing cooperative perception paradigms, such as Vehicle-to-Vehicle (V2V) and Vehicle-to-Infrastructure (V2I), have demonstrated their effectiveness in mitigating these challenges, they remain limited to ground-level collaboration and cannot fully address large-scale occlusions or long-range perception in complex environments. To advance research in cross-view cooperative perception, we present V2U4Real, the first large-scale real-world multi-modal dataset for Vehicle-to-UAV (V2U) cooperative object perception. V2U4Real is collected by a ground vehicle and a UAV equipped with multi-view LiDARs and RGB cameras. The dataset covers urban streets, university campuses, and rural roads under diverse traffic scenarios, comprising over 56K LiDAR frames, 56K multi-view camera images, and 700K annotated 3D bounding boxes across four classes. To support a wide range of research tasks, we establish benchmarks for single-agent 3D object detection, cooperative 3D object detection, and object tracking. Comprehensive evaluations of several state-of-the-art models demonstrate the effectiveness of V2U cooperation in enhancing perception robustness and long-range awareness. The V2U4Real dataset and codebase is available at https://github.com/VjiaLi/V2U4Real.
PPCR-IM: A System for Multi-layer DAG-based Public Policy Consequence Reasoning and Social Indicator Mapping
Feb 25, 2026Public policy decisions are typically justified using a narrow set of headline indicators, leaving many downstream social impacts unstructured and difficult to compare across policies. We propose PPCR-IM, a system for multi-layer DAG-based consequence reasoning and social indicator mapping that addresses this gap. Given a policy description and its context, PPCR-IM uses an LLM-driven, layer-wise generator to construct a directed acyclic graph of intermediate consequences, allowing child nodes to have multiple parents to capture joint influences. A mapping module then aligns these nodes to a fixed indicator set and assigns one of three qualitative impact directions: increase, decrease, or ambiguous change. For each policy episode, the system outputs a structured record containing the DAG, indicator mappings, and three evaluation measures: an expected-indicator coverage score, a discovery rate for overlooked but relevant indicators, and a relative focus ratio comparing the systems coverage to that of the government. PPCR-IM is available both as an online demo and as a configurable XLSX-to-JSON batch pipeline.
Mind-Brush: Integrating Agentic Cognitive Search and Reasoning into Image Generation
Feb 02, 2026While text-to-image generation has achieved unprecedented fidelity, the vast majority of existing models function fundamentally as static text-to-pixel decoders. Consequently, they often fail to grasp implicit user intentions. Although emerging unified understanding-generation models have improved intent comprehension, they still struggle to accomplish tasks involving complex knowledge reasoning within a single model. Moreover, constrained by static internal priors, these models remain unable to adapt to the evolving dynamics of the real world. To bridge these gaps, we introduce Mind-Brush, a unified agentic framework that transforms generation into a dynamic, knowledge-driven workflow. Simulating a human-like 'think-research-create' paradigm, Mind-Brush actively retrieves multimodal evidence to ground out-of-distribution concepts and employs reasoning tools to resolve implicit visual constraints. To rigorously evaluate these capabilities, we propose Mind-Bench, a comprehensive benchmark comprising 500 distinct samples spanning real-time news, emerging concepts, and domains such as mathematical and Geo-Reasoning. Extensive experiments demonstrate that Mind-Brush significantly enhances the capabilities of unified models, realizing a zero-to-one capability leap for the Qwen-Image baseline on Mind-Bench, while achieving superior results on established benchmarks like WISE and RISE.
IPCV: Information-Preserving Compression for MLLM Visual Encoders
Dec 21, 2025



Multimodal Large Language Models (MLLMs) deliver strong vision-language performance but at high computational cost, driven by numerous visual tokens processed by the Vision Transformer (ViT) encoder. Existing token pruning strategies are inadequate: LLM-stage token pruning overlooks the ViT's overhead, while conventional ViT token pruning, without language guidance, risks discarding textually critical visual cues and introduces feature distortions amplified by the ViT's bidirectional attention. To meet these challenges, we propose IPCV, a training-free, information-preserving compression framework for MLLM visual encoders. IPCV enables aggressive token pruning inside the ViT via Neighbor-Guided Reconstruction (NGR) that temporarily reconstructs pruned tokens to participate in attention with minimal overhead, then fully restores them before passing to the LLM. Besides, we introduce Attention Stabilization (AS) to further alleviate the negative influence from token pruning by approximating the K/V of pruned tokens. It can be directly applied to previous LLM-side token pruning methods to enhance their performance. Extensive experiments show that IPCV substantially reduces end-to-end computation and outperforms state-of-the-art training-free token compression methods across diverse image and video benchmarks. Our code is available at https://github.com/Perkzi/IPCV.
OmniAID: Decoupling Semantic and Artifacts for Universal AI-Generated Image Detection in the Wild
Nov 11, 2025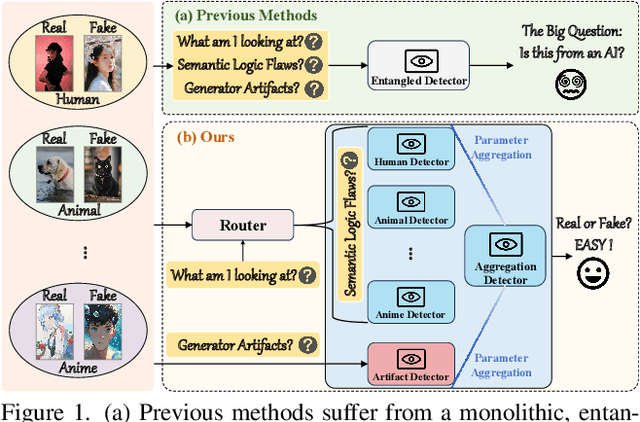
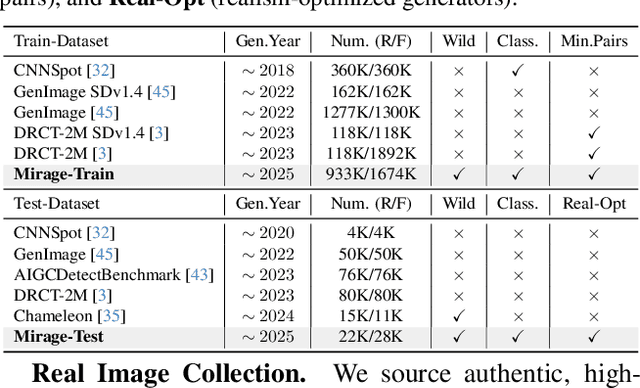
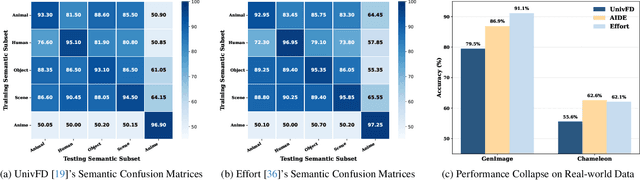
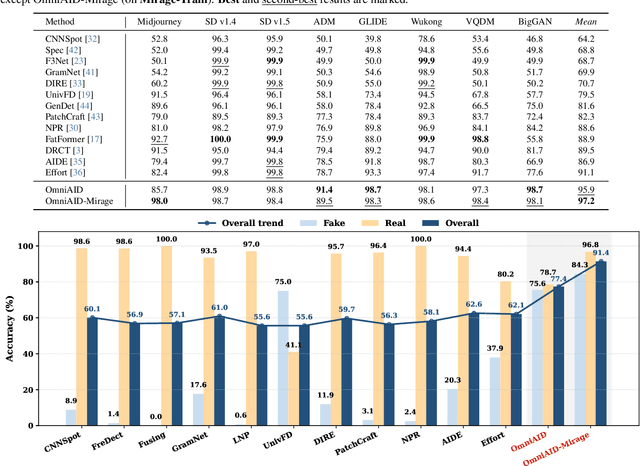
A truly universal AI-Generated Image (AIGI) detector must simultaneously generalize across diverse generative models and varied semantic content. Current state-of-the-art methods learn a single, entangled forgery representation--conflating content-dependent flaws with content-agnostic artifacts--and are further constrained by outdated benchmarks. To overcome these limitations, we propose OmniAID, a novel framework centered on a decoupled Mixture-of-Experts (MoE) architecture. The core of our method is a hybrid expert system engineered to decouple: (1) semantic flaws across distinct content domains, and (2) these content-dependent flaws from content-agnostic universal artifacts. This system employs a set of Routable Specialized Semantic Experts, each for a distinct domain (e.g., human, animal), complemented by a Fixed Universal Artifact Expert. This architecture is trained using a bespoke two-stage strategy: we first train the experts independently with domain-specific hard-sampling to ensure specialization, and subsequently train a lightweight gating network for effective input routing. By explicitly decoupling "what is generated" (content-specific flaws) from "how it is generated" (universal artifacts), OmniAID achieves robust generalization. To address outdated benchmarks and validate real-world applicability, we introduce Mirage, a new large-scale, contemporary dataset. Extensive experiments, using both traditional benchmarks and our Mirage dataset, demonstrate our model surpasses existing monolithic detectors, establishing a new, robust standard for AIGI authentication against modern, in-the-wild threats.
OmniLayout: Enabling Coarse-to-Fine Learning with LLMs for Universal Document Layout Generation
Oct 30, 2025Document AI has advanced rapidly and is attracting increasing attention. Yet, while most efforts have focused on document layout analysis (DLA), its generative counterpart, document layout generation, remains underexplored. A major obstacle lies in the scarcity of diverse layouts: academic papers with Manhattan-style structures dominate existing studies, while open-world genres such as newspapers and magazines remain severely underrepresented. To address this gap, we curate OmniLayout-1M, the first million-scale dataset of diverse document layouts, covering six common document types and comprising contemporary layouts collected from multiple sources. Moreover, since existing methods struggle in complex domains and often fail to arrange long sequences coherently, we introduce OmniLayout-LLM, a 0.5B model with designed two-stage Coarse-to-Fine learning paradigm: 1) learning universal layout principles from OmniLayout-1M with coarse category definitions, and 2) transferring the knowledge to a specific domain with fine-grained annotations. Extensive experiments demonstrate that our approach achieves strong performance on multiple domains in M$^{6}$Doc dataset, substantially surpassing both existing layout generation experts and several latest general-purpose LLMs. Our code, models, and dataset will be publicly released.
AudioMarathon: A Comprehensive Benchmark for Long-Context Audio Understanding and Efficiency in Audio LLMs
Oct 08, 2025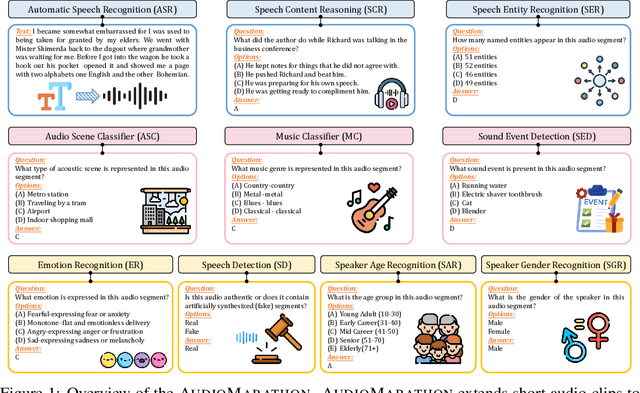
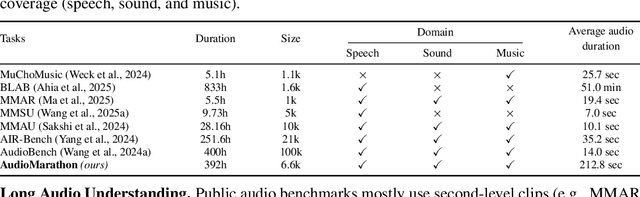
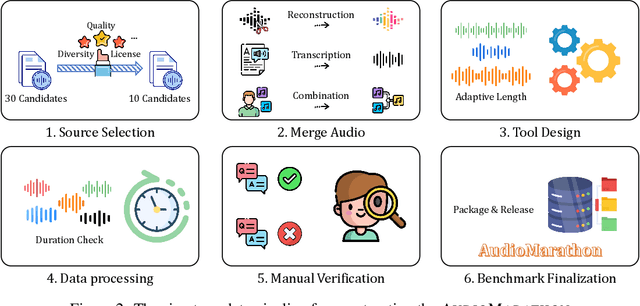

Processing long-form audio is a major challenge for Large Audio Language models (LALMs). These models struggle with the quadratic cost of attention ($O(N^2)$) and with modeling long-range temporal dependencies. Existing audio benchmarks are built mostly from short clips and do not evaluate models in realistic long context settings. To address this gap, we introduce AudioMarathon, a benchmark designed to evaluate both understanding and inference efficiency on long-form audio. AudioMarathon provides a diverse set of tasks built upon three pillars: long-context audio inputs with durations ranging from 90.0 to 300.0 seconds, which correspond to encoded sequences of 2,250 to 7,500 audio tokens, respectively, full domain coverage across speech, sound, and music, and complex reasoning that requires multi-hop inference. We evaluate state-of-the-art LALMs and observe clear performance drops as audio length grows. We also study acceleration techniques and analyze the trade-offs of token pruning and KV cache eviction. The results show large gaps across current LALMs and highlight the need for better temporal reasoning and memory-efficient architectures. We believe AudioMarathon will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.