 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoRight: Motion Control Done Right
Apr 08, 2026Generating motion-controlled videos--where user-specified actions drive physically plausible scene dynamics under freely chosen viewpoints--demands two capabilities: (1) disentangled motion control, allowing users to separately control the object motion and adjust camera viewpoint; and (2) motion causality, ensuring that user-driven actions trigger coherent reactions from other objects rather than merely displacing pixels. Existing methods fall short on both fronts: they entangle camera and object motion into a single tracking signal and treat motion as kinematic displacement without modeling causal relationships between object motion. We introduce MoRight, a unified framework that addresses both limitations through disentangled motion modeling. Object motion is specified in a canonical static-view and transferred to an arbitrary target camera viewpoint via temporal cross-view attention, enabling disentangled camera and object control. We further decompose motion into active (user-driven) and passive (consequence) components, training the model to learn motion causality from data. At inference, users can either supply active motion and MoRight predicts consequences (forward reasoning), or specify desired passive outcomes and MoRight recovers plausible driving actions (inverse reasoning), all while freely adjusting the camera viewpoint. Experiments on three benchmarks demonstrate state-of-the-art performance in generation quality, motion controllability, and interaction awareness.
Loop Closure via Maximal Cliques in 3D LiDAR-Based SLAM
Mar 05, 2026Reliable loop closure detection remains a critical challenge in 3D LiDAR-based SLAM, especially under sensor noise, environmental ambiguity, and viewpoint variation conditions. RANSAC is often used in the context of loop closures for geometric model fitting in the presence of outliers. However, this approach may fail, leading to map inconsistency. We introduce a novel deterministic algorithm, CliReg, for loop closure validation that replaces RANSAC verification with a maximal clique search over a compatibility graph of feature correspondences. This formulation avoids random sampling and increases robustness in the presence of noise and outliers. We integrated our approach into a real- time pipeline employing binary 3D descriptors and a Hamming distance embedding binary search tree-based matching. We evaluated it on multiple real-world datasets featuring diverse LiDAR sensors. The results demonstrate that our proposed technique consistently achieves a lower pose error and more reliable loop closures than RANSAC, especially in sparse or ambiguous conditions. Additional experiments on 2D projection-based maps confirm its generality across spatial domains, making our approach a robust and efficient alternative for loop closure detection.
Learning Humanoid End-Effector Control for Open-Vocabulary Visual Loco-Manipulation
Feb 18, 2026Visual loco-manipulation of arbitrary objects in the wild with humanoid robots requires accurate end-effector (EE) control and a generalizable understanding of the scene via visual inputs (e.g., RGB-D images). Existing approaches are based on real-world imitation learning and exhibit limited generalization due to the difficulty in collecting large-scale training datasets. This paper presents a new paradigm, HERO, for object loco-manipulation with humanoid robots that combines the strong generalization and open-vocabulary understanding of large vision models with strong control performance from simulated training. We achieve this by designing an accurate residual-aware EE tracking policy. This EE tracking policy combines classical robotics with machine learning. It uses a) inverse kinematics to convert residual end-effector targets into reference trajectories, b) a learned neural forward model for accurate forward kinematics, c) goal adjustment, and d) replanning. Together, these innovations help us cut down the end-effector tracking error by 3.2x. We use this accurate end-effector tracker to build a modular system for loco-manipulation, where we use open-vocabulary large vision models for strong visual generalization. Our system is able to operate in diverse real-world environments, from offices to coffee shops, where the robot is able to reliably manipulate various everyday objects (e.g., mugs, apples, toys) on surfaces ranging from 43cm to 92cm in height. Systematic modular and end-to-end tests in simulation and the real world demonstrate the effectiveness of our proposed design. We believe the advances in this paper can open up new ways of training humanoid robots to interact with daily objects.
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
May 30, 2025This paper presents AlphaOne ($\alpha$1), a universal framework for modulating reasoning progress in large reasoning models (LRMs) at test time. $\alpha$1 first introduces $\alpha$ moment, which represents the scaled thinking phase with a universal parameter $\alpha$. Within this scaled pre-$\alpha$ moment phase, it dynamically schedules slow thinking transitions by modeling the insertion of reasoning transition tokens as a Bernoulli stochastic process. After the $\alpha$ moment, $\alpha$1 deterministically terminates slow thinking with the end-of-thinking token, thereby fostering fast reasoning and efficient answer generation. This approach unifies and generalizes existing monotonic scaling methods by enabling flexible and dense slow-to-fast reasoning modulation. Extensive empirical studies on various challenging benchmarks across mathematical, coding, and scientific domains demonstrate $\alpha$1's superior reasoning capability and efficiency. Project page: https://alphaone-project.github.io/
How Do I Do That? Synthesizing 3D Hand Motion and Contacts for Everyday Interactions
Apr 16, 2025



We tackle the novel problem of predicting 3D hand motion and contact maps (or Interaction Trajectories) given a single RGB view, action text, and a 3D contact point on the object as input. Our approach consists of (1) Interaction Codebook: a VQVAE model to learn a latent codebook of hand poses and contact points, effectively tokenizing interaction trajectories, (2) Interaction Predictor: a transformer-decoder module to predict the interaction trajectory from test time inputs by using an indexer module to retrieve a latent affordance from the learned codebook. To train our model, we develop a data engine that extracts 3D hand poses and contact trajectories from the diverse HoloAssist dataset. We evaluate our model on a benchmark that is 2.5-10X larger than existing works, in terms of diversity of objects and interactions observed, and test for generalization of the model across object categories, action categories, tasks, and scenes. Experimental results show the effectiveness of our approach over transformer & diffusion baselines across all settings.
3D Object Reconstruction with mmWave Radars
Apr 15, 2025This paper presents RFconstruct, a framework that enables 3D shape reconstruction using commercial off-the-shelf (COTS) mmWave radars for self-driving scenarios. RFconstruct overcomes radar limitations of low angular resolution, specularity, and sparsity in radar point clouds through a holistic system design that addresses hardware, data processing, and machine learning challenges. The first step is fusing data captured by two radar devices that image orthogonal planes, then performing odometry-aware temporal fusion to generate denser 3D point clouds. RFconstruct then reconstructs 3D shapes of objects using a customized encoder-decoder model that does not require prior knowledge of the object's bound box. The shape reconstruction performance of RFconstruct is compared against 3D models extracted from a depth camera equipped with a LiDAR. We show that RFconstruct can accurately generate 3D shapes of cars, bikes, and pedestrians.
PhysGen3D: Crafting a Miniature Interactive World from a Single Image
Mar 26, 2025Envisioning physically plausible outcomes from a single image requires a deep understanding of the world's dynamics. To address this, we introduce PhysGen3D, a novel framework that transforms a single image into an amodal, camera-centric, interactive 3D scene. By combining advanced image-based geometric and semantic understanding with physics-based simulation, PhysGen3D creates an interactive 3D world from a static image, enabling us to "imagine" and simulate future scenarios based on user input. At its core, PhysGen3D estimates 3D shapes, poses, physical and lighting properties of objects, thereby capturing essential physical attributes that drive realistic object interactions. This framework allows users to specify precise initial conditions, such as object speed or material properties, for enhanced control over generated video outcomes. We evaluate PhysGen3D's performance against closed-source state-of-the-art (SOTA) image-to-video models, including Pika, Kling, and Gen-3, showing PhysGen3D's capacity to generate videos with realistic physics while offering greater flexibility and fine-grained control. Our results show that PhysGen3D achieves a unique balance of photorealism, physical plausibility, and user-driven interactivity, opening new possibilities for generating dynamic, physics-grounded video from an image.
KISS-SLAM: A Simple, Robust, and Accurate 3D LiDAR SLAM System With Enhanced Generalization Capabilities
Mar 16, 2025



Robust and accurate localization and mapping of an environment using laser scanners, so-called LiDAR SLAM, is essential to many robotic applications. Early 3D LiDAR SLAM methods often exploited additional information from IMU or GNSS sensors to enhance localization accuracy and mitigate drift. Later, advanced systems further improved the estimation at the cost of a higher runtime and complexity. This paper explores the limits of what can be achieved with a LiDAR-only SLAM approach while following the "Keep It Small and Simple" (KISS) principle. By leveraging this minimalistic design principle, our system, KISS-SLAM, archives state-of-the-art performances in pose accuracy while requiring little to no parameter tuning for deployment across diverse environments, sensors, and motion profiles. We follow best practices in graph-based SLAM and build upon LiDAR odometry to compute the relative motion between scans and construct local maps of the environment. To correct drift, we match local maps and optimize the trajectory in a pose graph optimization step. The experimental results demonstrate that this design achieves competitive performance while reducing complexity and reliance on additional sensor modalities. By prioritizing simplicity, this work provides a new strong baseline for LiDAR-only SLAM and a high-performing starting point for future research. Further, our pipeline builds consistent maps that can be used directly for further downstream tasks like navigation. Our open-source system operates faster than the sensor frame rate in all presented datasets and is designed for real-world scenarios.
A Training-Free Framework for Precise Mobile Manipulation of Small Everyday Objects
Feb 19, 2025Many everyday mobile manipulation tasks require precise interaction with small objects, such as grasping a knob to open a cabinet or pressing a light switch. In this paper, we develop Servoing with Vision Models (SVM), a closed-loop training-free framework that enables a mobile manipulator to tackle such precise tasks involving the manipulation of small objects. SVM employs an RGB-D wrist camera and uses visual servoing for control. Our novelty lies in the use of state-of-the-art vision models to reliably compute 3D targets from the wrist image for diverse tasks and under occlusion due to the end-effector. To mitigate occlusion artifacts, we employ vision models to out-paint the end-effector thereby significantly enhancing target localization. We demonstrate that aided by out-painting methods, open-vocabulary object detectors can serve as a drop-in module to identify semantic targets (e.g. knobs) and point tracking methods can reliably track interaction sites indicated by user clicks. This training-free method obtains an 85% zero-shot success rate on manipulating unseen objects in novel environments in the real world, outperforming an open-loop control method and an imitation learning baseline trained on 1000+ demonstrations by an absolute success rate of 50%.
Learning Getting-Up Policies for Real-World Humanoid Robots
Feb 17, 2025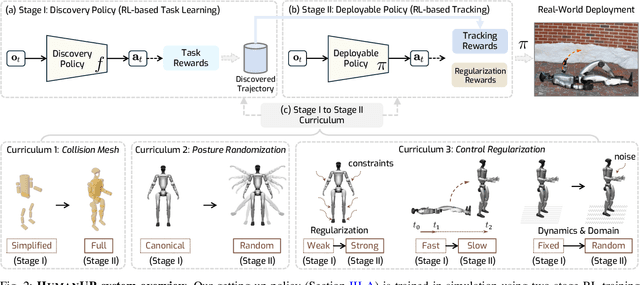
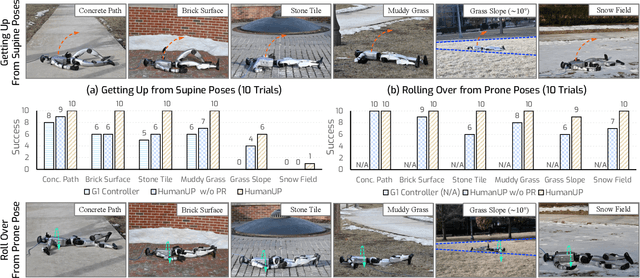
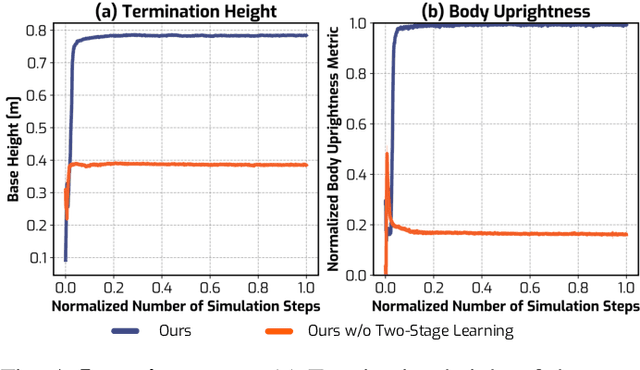
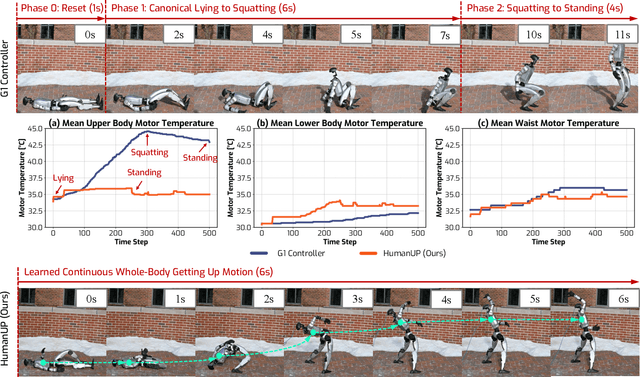
Automatic fall recovery is a crucial prerequisite before humanoid robots can be reliably deployed. Hand-designing controllers for getting up is difficult because of the varied configurations a humanoid can end up in after a fall and the challenging terrains humanoid robots are expected to operate on. This paper develops a learning framework to produce controllers that enable humanoid robots to get up from varying configurations on varying terrains. Unlike previous successful applications of humanoid locomotion learning, the getting-up task involves complex contact patterns, which necessitates accurately modeling the collision geometry and sparser rewards. We address these challenges through a two-phase approach that follows a curriculum. The first stage focuses on discovering a good getting-up trajectory under minimal constraints on smoothness or speed / torque limits. The second stage then refines the discovered motions into deployable (i.e. smooth and slow) motions that are robust to variations in initial configuration and terrains. We find these innovations enable a real-world G1 humanoid robot to get up from two main situations that we considered: a) lying face up and b) lying face down, both tested on flat, deformable, slippery surfaces and slopes (e.g., sloppy grass and snowfield). To the best of our knowledge, this is the first successful demonstration of learned getting-up policies for human-sized humanoid robots in the real world. Project page: https://humanoid-getup.github.io/