 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning-free Visual Effect Transfer across Videos
Jan 13, 2026We present RefVFX, a new framework that transfers complex temporal effects from a reference video onto a target video or image in a feed-forward manner. While existing methods excel at prompt-based or keyframe-conditioned editing, they struggle with dynamic temporal effects such as dynamic lighting changes or character transformations, which are difficult to describe via text or static conditions. Transferring a video effect is challenging, as the model must integrate the new temporal dynamics with the input video's existing motion and appearance. % To address this, we introduce a large-scale dataset of triplets, where each triplet consists of a reference effect video, an input image or video, and a corresponding output video depicting the transferred effect. Creating this data is non-trivial, especially the video-to-video effect triplets, which do not exist naturally. To generate these, we propose a scalable automated pipeline that creates high-quality paired videos designed to preserve the input's motion and structure while transforming it based on some fixed, repeatable effect. We then augment this data with image-to-video effects derived from LoRA adapters and code-based temporal effects generated through programmatic composition. Building on our new dataset, we train our reference-conditioned model using recent text-to-video backbones. Experimental results demonstrate that RefVFX produces visually consistent and temporally coherent edits, generalizes across unseen effect categories, and outperforms prompt-only baselines in both quantitative metrics and human preference. See our website https://tuningfreevisualeffects-maker.github.io/Tuning-free-Visual-Effect-Transfer-across-Videos-Project-Page/
Omni-Attribute: Open-vocabulary Attribute Encoder for Visual Concept Personalization
Dec 11, 2025Visual concept personalization aims to transfer only specific image attributes, such as identity, expression, lighting, and style, into unseen contexts. However, existing methods rely on holistic embeddings from general-purpose image encoders, which entangle multiple visual factors and make it difficult to isolate a single attribute. This often leads to information leakage and incoherent synthesis. To address this limitation, we introduce Omni-Attribute, the first open-vocabulary image attribute encoder designed to learn high-fidelity, attribute-specific representations. Our approach jointly designs the data and model: (i) we curate semantically linked image pairs annotated with positive and negative attributes to explicitly teach the encoder what to preserve or suppress; and (ii) we adopt a dual-objective training paradigm that balances generative fidelity with contrastive disentanglement. The resulting embeddings prove effective for open-vocabulary attribute retrieval, personalization, and compositional generation, achieving state-of-the-art performance across multiple benchmarks.
Fast Data Attribution for Text-to-Image Models
Nov 13, 2025Data attribution for text-to-image models aims to identify the training images that most significantly influenced a generated output. Existing attribution methods involve considerable computational resources for each query, making them impractical for real-world applications. We propose a novel approach for scalable and efficient data attribution. Our key idea is to distill a slow, unlearning-based attribution method to a feature embedding space for efficient retrieval of highly influential training images. During deployment, combined with efficient indexing and search methods, our method successfully finds highly influential images without running expensive attribution algorithms. We show extensive results on both medium-scale models trained on MSCOCO and large-scale Stable Diffusion models trained on LAION, demonstrating that our method can achieve better or competitive performance in a few seconds, faster than existing methods by 2,500x - 400,000x. Our work represents a meaningful step towards the large-scale application of data attribution methods on real-world models such as Stable Diffusion.
Learning an Image Editing Model without Image Editing Pairs
Oct 16, 2025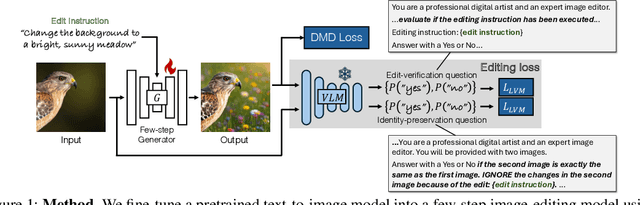
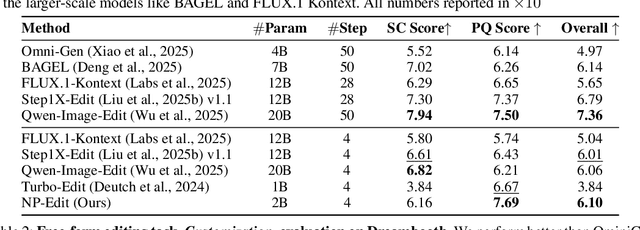

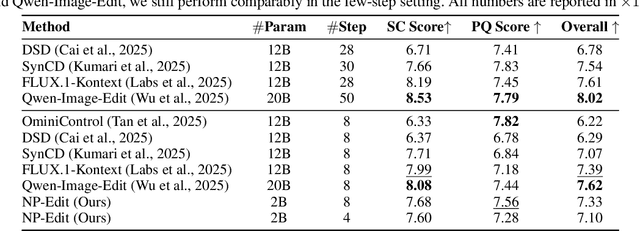
Recent image editing models have achieved impressive results while following natural language editing instructions, but they rely on supervised fine-tuning with large datasets of input-target pairs. This is a critical bottleneck, as such naturally occurring pairs are hard to curate at scale. Current workarounds use synthetic training pairs that leverage the zero-shot capabilities of existing models. However, this can propagate and magnify the artifacts of the pretrained model into the final trained model. In this work, we present a new training paradigm that eliminates the need for paired data entirely. Our approach directly optimizes a few-step diffusion model by unrolling it during training and leveraging feedback from vision-language models (VLMs). For each input and editing instruction, the VLM evaluates if an edit follows the instruction and preserves unchanged content, providing direct gradients for end-to-end optimization. To ensure visual fidelity, we incorporate distribution matching loss (DMD), which constrains generated images to remain within the image manifold learned by pretrained models. We evaluate our method on standard benchmarks and include an extensive ablation study. Without any paired data, our method performs on par with various image editing diffusion models trained on extensive supervised paired data, under the few-step setting. Given the same VLM as the reward model, we also outperform RL-based techniques like Flow-GRPO.
Prompt-to-Product: Generative Assembly via Bimanual Manipulation
Aug 28, 2025

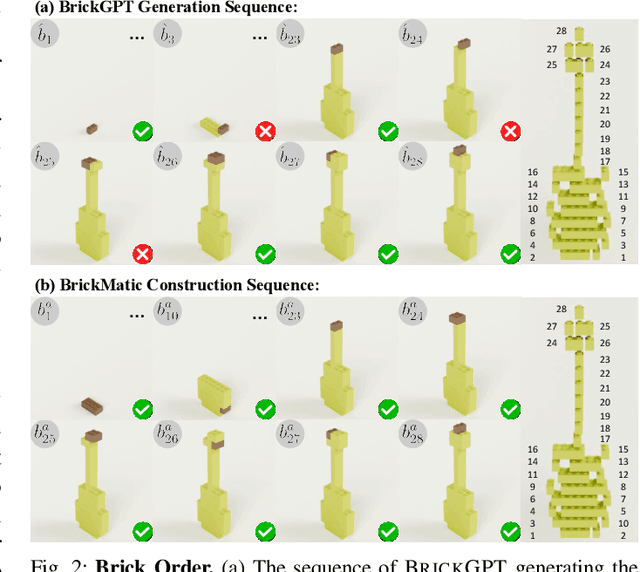
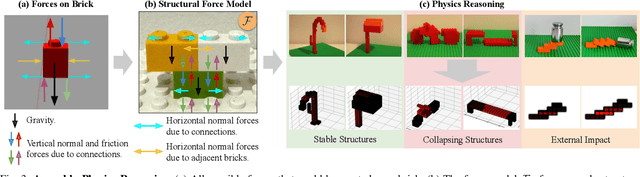
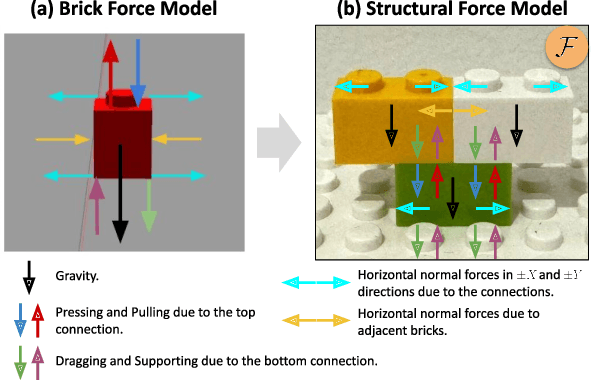
Creating assembly products demands significant manual effort and expert knowledge in 1) designing the assembly and 2) constructing the product. This paper introduces Prompt-to-Product, an automated pipeline that generates real-world assembly products from natural language prompts. Specifically, we leverage LEGO bricks as the assembly platform and automate the process of creating brick assembly structures. Given the user design requirements, Prompt-to-Product generates physically buildable brick designs, and then leverages a bimanual robotic system to construct the real assembly products, bringing user imaginations into the real world. We conduct a comprehensive user study, and the results demonstrate that Prompt-to-Product significantly lowers the barrier and reduces manual effort in creating assembly products from imaginative ideas.
Scaling Group Inference for Diverse and High-Quality Generation
Aug 21, 2025Generative models typically sample outputs independently, and recent inference-time guidance and scaling algorithms focus on improving the quality of individual samples. However, in real-world applications, users are often presented with a set of multiple images (e.g., 4-8) for each prompt, where independent sampling tends to lead to redundant results, limiting user choices and hindering idea exploration. In this work, we introduce a scalable group inference method that improves both the diversity and quality of a group of samples. We formulate group inference as a quadratic integer assignment problem: candidate outputs are modeled as graph nodes, and a subset is selected to optimize sample quality (unary term) while maximizing group diversity (binary term). To substantially improve runtime efficiency, we progressively prune the candidate set using intermediate predictions, allowing our method to scale up to large candidate sets. Extensive experiments show that our method significantly improves group diversity and quality compared to independent sampling baselines and recent inference algorithms. Our framework generalizes across a wide range of tasks, including text-to-image, image-to-image, image prompting, and video generation, enabling generative models to treat multiple outputs as cohesive groups rather than independent samples.
Identifying Prompted Artist Names from Generated Images
Jul 24, 2025A common and controversial use of text-to-image models is to generate pictures by explicitly naming artists, such as "in the style of Greg Rutkowski". We introduce a benchmark for prompted-artist recognition: predicting which artist names were invoked in the prompt from the image alone. The dataset contains 1.95M images covering 110 artists and spans four generalization settings: held-out artists, increasing prompt complexity, multiple-artist prompts, and different text-to-image models. We evaluate feature similarity baselines, contrastive style descriptors, data attribution methods, supervised classifiers, and few-shot prototypical networks. Generalization patterns vary: supervised and few-shot models excel on seen artists and complex prompts, whereas style descriptors transfer better when the artist's style is pronounced; multi-artist prompts remain the most challenging. Our benchmark reveals substantial headroom and provides a public testbed to advance the responsible moderation of text-to-image models. We release the dataset and benchmark to foster further research: https://graceduansu.github.io/IdentifyingPromptedArtists/
Generating Physically Stable and Buildable LEGO Designs from Text
May 08, 2025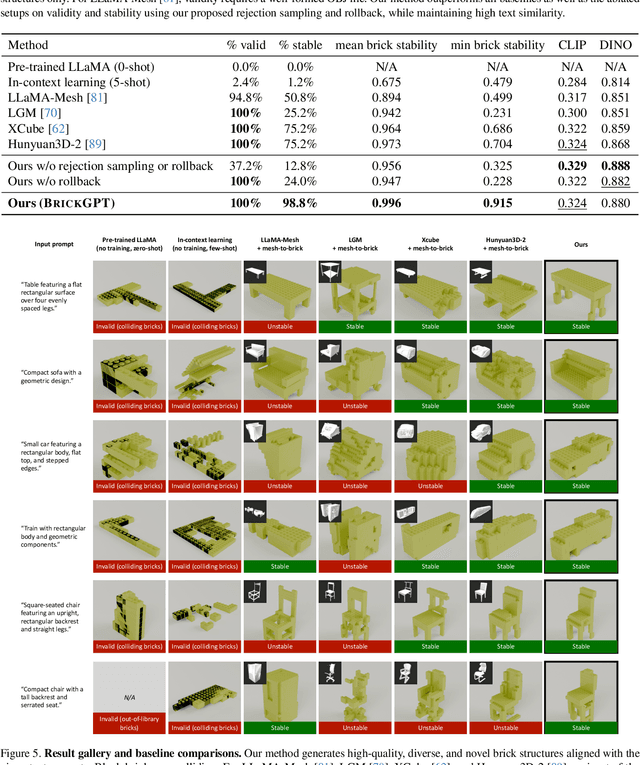
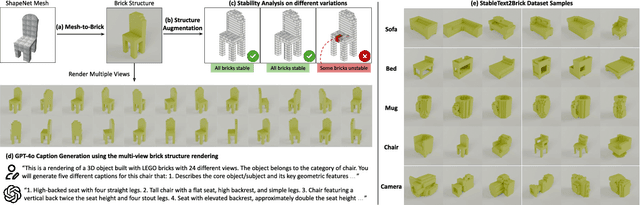
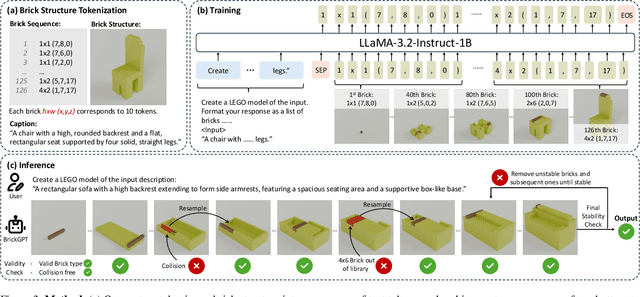
We introduce LegoGPT, the first approach for generating physically stable LEGO brick models from text prompts. To achieve this, we construct a large-scale, physically stable dataset of LEGO designs, along with their associated captions, and train an autoregressive large language model to predict the next brick to add via next-token prediction. To improve the stability of the resulting designs, we employ an efficient validity check and physics-aware rollback during autoregressive inference, which prunes infeasible token predictions using physics laws and assembly constraints. Our experiments show that LegoGPT produces stable, diverse, and aesthetically pleasing LEGO designs that align closely with the input text prompts. We also develop a text-based LEGO texturing method to generate colored and textured designs. We show that our designs can be assembled manually by humans and automatically by robotic arms. We also release our new dataset, StableText2Lego, containing over 47,000 LEGO structures of over 28,000 unique 3D objects accompanied by detailed captions, along with our code and models at the project website: https://avalovelace1.github.io/LegoGPT/.
Efficient Autoregressive Shape Generation via Octree-Based Adaptive Tokenization
Apr 03, 2025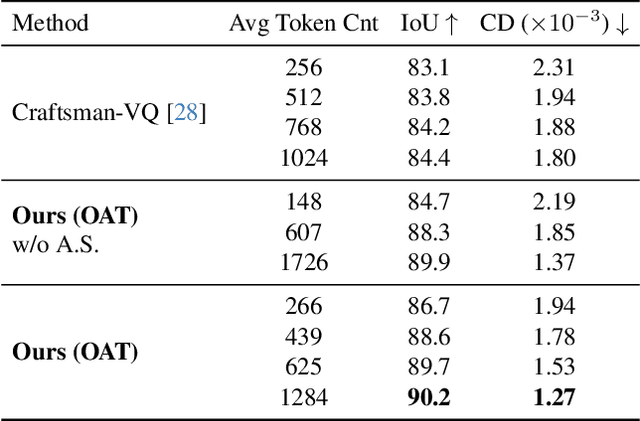

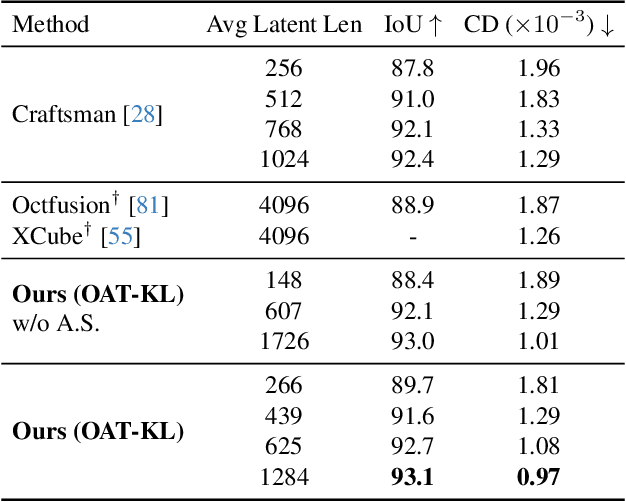
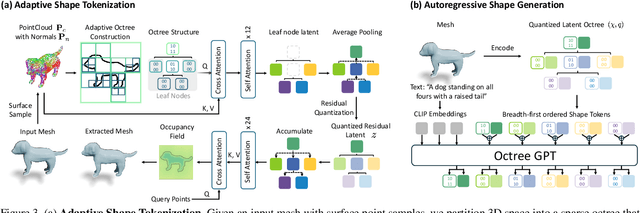
Many 3D generative models rely on variational autoencoders (VAEs) to learn compact shape representations. However, existing methods encode all shapes into a fixed-size token, disregarding the inherent variations in scale and complexity across 3D data. This leads to inefficient latent representations that can compromise downstream generation. We address this challenge by introducing Octree-based Adaptive Tokenization, a novel framework that adjusts the dimension of latent representations according to shape complexity. Our approach constructs an adaptive octree structure guided by a quadric-error-based subdivision criterion and allocates a shape latent vector to each octree cell using a query-based transformer. Building upon this tokenization, we develop an octree-based autoregressive generative model that effectively leverages these variable-sized representations in shape generation. Extensive experiments demonstrate that our approach reduces token counts by 50% compared to fixed-size methods while maintaining comparable visual quality. When using a similar token length, our method produces significantly higher-quality shapes. When incorporated with our downstream generative model, our method creates more detailed and diverse 3D content than existing approaches.
Generating Multi-Image Synthetic Data for Text-to-Image Customization
Feb 03, 2025Customization of text-to-image models enables users to insert custom concepts and generate the concepts in unseen settings. Existing methods either rely on costly test-time optimization or train encoders on single-image training datasets without multi-image supervision, leading to worse image quality. We propose a simple approach that addresses both limitations. We first leverage existing text-to-image models and 3D datasets to create a high-quality Synthetic Customization Dataset (SynCD) consisting of multiple images of the same object in different lighting, backgrounds, and poses. We then propose a new encoder architecture based on shared attention mechanisms that better incorporate fine-grained visual details from input images. Finally, we propose a new inference technique that mitigates overexposure issues during inference by normalizing the text and image guidance vectors. Through extensive experiments, we show that our model, trained on the synthetic dataset with the proposed encoder and inference algorithm, outperforms existing tuning-free methods on standard customization benchmarks.